基于 Nebula Graph 構(gòu)建圖學(xué)習(xí)能力

經(jīng)常看技術(shù)文章的小伙伴可能會留意到除了正在閱讀的那篇文章,在文章頁面的正文下方或者右側(cè)區(qū)域會有若干同主題、同作者的文章等你閱讀;經(jīng)常逛淘寶、京東的小伙伴可能發(fā)現(xiàn)了,一旦你購買或者查看過某個商品之后,猜你喜歡的推薦商品會貼近你剛拔草的商品…這些日常生活中常遇到的事情,可能是由一個名叫圖學(xué)習(xí)的“家伙”提供技術(shù)支持。
圖學(xué)習(xí),顧名思義是基于圖的機器學(xué)習(xí),按照本期項目介紹的參賽隊伍——圖學(xué)習(xí)興趣小隊隊長楊鑫的話就是,圖學(xué)習(xí)是一個通過深度學(xué)習(xí)方法,基于圖的結(jié)構(gòu)與屬性生成一個向量作為點、邊或者整個圖的表征。
在之前 Nebula Hackathon 2021 年的參賽項目中,圖學(xué)習(xí)興趣小隊“豪氣”地說要讓 Nebula Graph 具備支持圖學(xué)習(xí)的能力,在本文接下來的內(nèi)容中,你將了解到他們是怎么實現(xiàn)這一目標(biāo)的。
在講述項目實現(xiàn)之前,項目負責(zé)人楊鑫先給大家上了一課“圖解圖學(xué)習(xí)”。
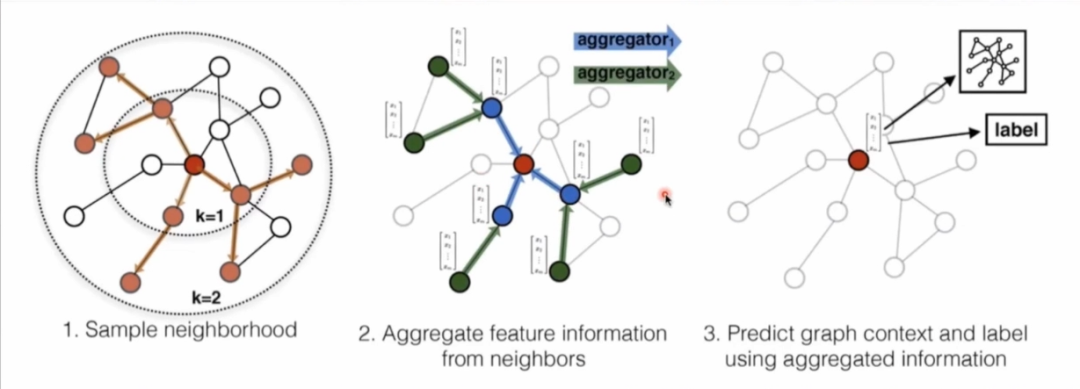
以獲取頂點的向量表征為例來講解下圖學(xué)習(xí)過程,第一步需要對圖中頂點鄰居進行采樣拿到鄰居的拓撲結(jié)構(gòu)以及屬性;第二步便是通過自定義的聚合函數(shù)聚合鄰居頂點蘊含的信息進行計算;最后一步基于聚合信息得到圖中各頂點的向量表示。
楊鑫表示,衡量一個圖學(xué)習(xí)算法的好壞是通過生成向量中包含圖中頂點屬性及拓撲結(jié)構(gòu)的豐富程度來判斷的。
在選擇圖學(xué)習(xí)框架時,圖學(xué)習(xí)興趣小隊有自己的一套選型標(biāo)準(zhǔn):首先它是開源組件,方便二次開發(fā),其次它支持分布式,最后框架本身和圖數(shù)據(jù)庫的耦合程度要低方便定制化開發(fā)。經(jīng)過深入調(diào)研,由于 DGL 同底層的圖數(shù)據(jù)庫耦合過高,PYG 不支持分布式,最終他們采用了 Euler,而在 Nebula Hackathon 2021 中,圖學(xué)習(xí)興趣小隊的重點工作便是用 Nebula Graph 替換 Euler 原生圖數(shù)據(jù)庫,讓社區(qū)用戶可以基于 Nebula Graph 低成本嘗試圖學(xué)習(xí)能力。
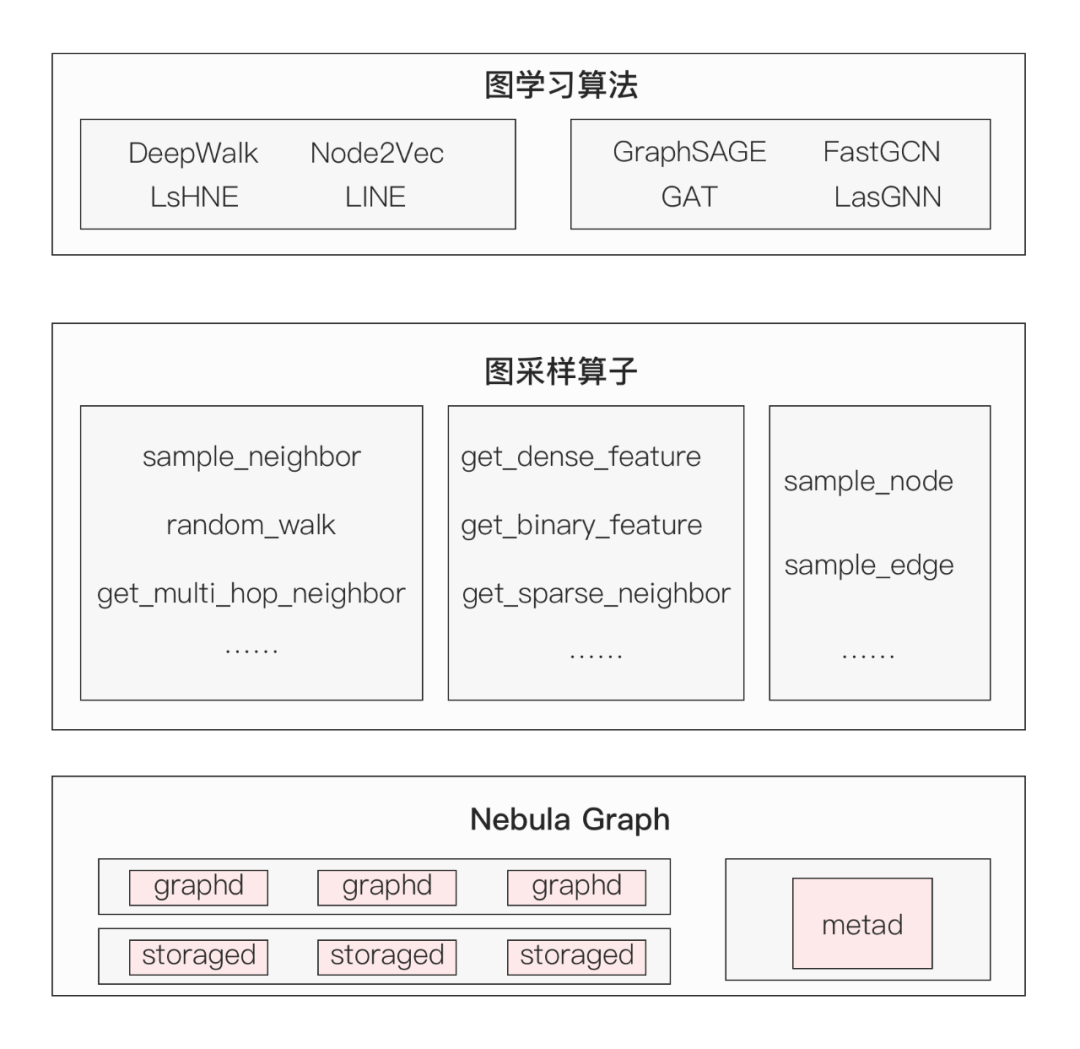
在方案設(shè)計上,架構(gòu)分為三層:底層是 Nebula Graph 圖數(shù)據(jù)庫,中間層是圖采樣算子層,為上層 Euler 圖算法提供多種采樣圖數(shù)據(jù)的能力。圖采樣算子則是他們本次工作的重點——重寫 22 個 TF 采樣算子、6 種 nGQL 采樣語法。
以全局帶權(quán)采樣語法設(shè)計為例,
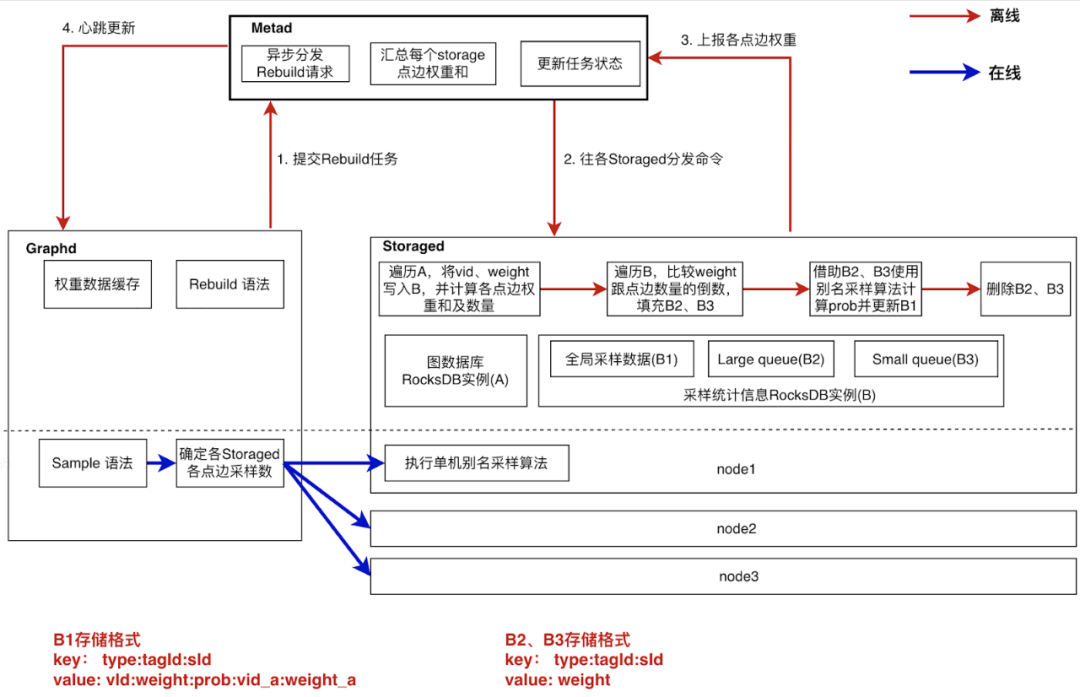
這里采用了預(yù)計算(離線)+ 計算下推(實時)的方式來實現(xiàn)全局采樣,主要過程為(上圖 1-4)
- graphd 提交異步構(gòu)建任務(wù)給 metad;
- metad 下發(fā)任務(wù)給各個 storaged 節(jié)點進行計算;
- storaged 將計算結(jié)果上報給 metad 匯總;
- metad 通過心跳將結(jié)果同步給 graphd。
詳細展開來講,在圖學(xué)習(xí)訓(xùn)練過程中,數(shù)據(jù)采樣是一個非常高頻的操作,采樣性能好壞對圖學(xué)習(xí)訓(xùn)練耗時影響很大。
在這里,楊鑫他們采用別名采樣算法作為全局帶權(quán)采樣語法的核心算法,它的基本原理是首先對進行采樣的全部數(shù)據(jù)根據(jù)各自的權(quán)重計算出一份采樣表,采樣表由行號(sid)、vid1、采樣概率(prob)、vid2 四部分組成,其中行號是從 0 開始的編號,vid1、vid2 表示可以被采樣的某個頂點的 vid;采樣流程是首先在表中隨機選擇一行,然后再隨機生成一個 0~1 之間的值 p,如果 p < prob,則本次采樣的數(shù)據(jù)是 vid1,否則采樣 vid2。
目前圖學(xué)習(xí)是基于靜態(tài)圖數(shù)據(jù)訓(xùn)練,因此我們可以通過預(yù)計算的方式離線生成一份別名采樣表,而實時采樣過程簡化為基于預(yù)計算的采樣表做兩次隨機采樣,時間復(fù)雜度由 O(n) 降到 O(1),可以極大地提高采樣效率。
下面是基于 Nebula Graph 實現(xiàn)的全局帶權(quán)采樣具體實現(xiàn),跟 Nebula Graph 的索引重建邏輯很相似。
- Graph 服務(wù)調(diào)用 Meta 服務(wù)啟動一個異步構(gòu)建采樣表任務(wù),并支持異步任務(wù)的狀態(tài)查詢。
- Meta 服務(wù)的作用是控制異步任務(wù)的執(zhí)行,包括分配每個 Storage 節(jié)點需要處理的數(shù)據(jù)(根據(jù) partition 的 leader 分布決定)、異步觸發(fā)各個 Storage 節(jié)點進行采樣表的計算、記錄任務(wù)的執(zhí)行狀態(tài)、記錄全局信息(點、邊權(quán)重和)、通過心跳邏輯將全局信息緩存在 Graph 服務(wù)中。
- Storage 服務(wù)的任務(wù)是生成所負責(zé)數(shù)據(jù)的采樣表。采樣表的計算是整個流程中的核心邏輯,計算過程需要對所有點、邊編號,并根據(jù)權(quán)重大小對點、邊進行分類,很顯然這些數(shù)據(jù)是無法全部存儲在內(nèi)存中的,所以我們在 Storage 中增加了一個采樣統(tǒng)計信息 RocksDB 實例來存儲采樣表、點邊總數(shù)、點邊權(quán)重、計算中間變量等數(shù)據(jù)。以計算某一類點的采樣表的過程為例:
第一步遍歷全圖來統(tǒng)計這一類點的權(quán)重和數(shù)量,同時為了給生成采樣表做準(zhǔn)備,將點的序號(點的讀取順序)、vid、權(quán)重等數(shù)據(jù)存儲在了圖中(B1)結(jié)構(gòu)中。其中 key 的數(shù)據(jù)結(jié)構(gòu)是 type + tagid + sid,type 標(biāo)識了數(shù)據(jù)是 B1 類型,tagid 就是點的 tag,sid 是點的序號,跟采樣表的 key 結(jié)構(gòu)相同。
第二步將數(shù)據(jù)分類,根據(jù)權(quán)重值以點的總數(shù)的倒數(shù)為界將所有的點分成兩部分,分別以(B2)、(B3)的結(jié)構(gòu)存儲,key 的組成與 (B1) 結(jié)構(gòu)相比就是type 值不同。
第三步分別遍歷(B2)、(B3),根據(jù)別名采樣算法的理論來計算每個點的采樣概率 prob。這里每個點是用 sid 來標(biāo)識的,也就是說實際上是在計算第 sid 個點的采樣概率,概率值作為采樣表的一部分會更新到(B1)結(jié)構(gòu)中。
第四步將中間變量(B2)、(B3)結(jié)構(gòu)刪除掉,釋放磁盤空間。
利用采樣表進行實時采樣的過程就比較簡單了。完成采樣表的預(yù)計算后會將點、邊權(quán)重的統(tǒng)計信息上報到 Meta 服務(wù)存儲,然后通過心跳通知 Graph 服務(wù)將這些數(shù)據(jù)緩存在本地。根據(jù)這些數(shù)據(jù)可以計算出點、邊在各 Storage 服務(wù)上所占的權(quán)重比例,將用戶指定的采樣數(shù)量按比例分配到各 Storage 服務(wù),然后在 Storage 服務(wù)上通過兩次的隨機數(shù)操作采樣到足夠數(shù)量的數(shù)據(jù)后返回,最后在 Graph 服務(wù)上進行數(shù)據(jù)聚合,這樣就完成了一次帶權(quán)采樣。
另外為了提高異步任務(wù)的健壯性,還實現(xiàn)了失敗重試、任務(wù)重復(fù)限制、重建采樣表后臟數(shù)據(jù)清理、導(dǎo)出采樣表等功能。
提到項目設(shè)計以及重寫其他算子過程中遇到的問題,圖學(xué)習(xí)興趣小隊隊長楊鑫表示因為 Nebula Graph 的數(shù)據(jù)都存儲在磁盤中,要用 Nebula Graph 替換 Euler 原生內(nèi)存圖數(shù)據(jù)庫,改造后的 Euler 在采樣效率上肯定要低于原生 Euler,因此怎么保證改造后 Euler 的圖學(xué)習(xí)訓(xùn)練耗時盡可能接近原生 Euler 是要解決的首要問題,至少得保證兩者采樣性能不能有數(shù)據(jù)級上的差距。
原生 Euler 中的圖學(xué)習(xí)算法由 Python 實現(xiàn),通過 TensorFlow 的 OP 機制來調(diào)用 C++ 實現(xiàn)的采樣算子,然后在采樣算子內(nèi)直接調(diào)用內(nèi)存圖數(shù)據(jù)庫獲取數(shù)據(jù),這樣就完成了一次數(shù)據(jù)采樣。
圖興趣小隊最初的方案是將采樣算子用 Python 實現(xiàn),這樣一次數(shù)據(jù)采樣過程就變成了圖學(xué)習(xí)算法直接調(diào)用采樣算子,然后在采樣算子內(nèi)則通過 Nebula Graph 的 Python 客戶端執(zhí)行采樣語法獲取數(shù)據(jù)。這樣改造后的系統(tǒng)會有更清晰的處理流程,但是經(jīng)過測試他們發(fā)現(xiàn)其訓(xùn)練耗時要遠大于原生 Euler,具體到訓(xùn)練過程中的每次數(shù)據(jù)采樣上,其耗時是原生 Euler 的幾十倍,這樣的結(jié)果顯然是不能滿足要求的。通過分析各階段執(zhí)行耗時他們發(fā)現(xiàn),數(shù)據(jù)采樣的耗時要遠大于采樣語法的執(zhí)行耗時,所以他們認為是 Python 客戶端在反序列化上消耗了大量時間。因此圖興趣小隊進行了第一次優(yōu)化,使用 fbthrift fastproto 替換 Nebula Graph 原生客戶端的序列化組件,優(yōu)化后的性能提高了一倍,整體訓(xùn)練耗時確實有所降低,但是這樣的結(jié)果卻仍然無法滿足他們的使用要求。
這時候用上了第二個方案,重寫 C++ 版本的采樣算子,在采樣算子中通過 Nebula Graph 的 C++ 客戶端執(zhí)行采樣語法獲取數(shù)據(jù),相比第一個方案多了一些適配工作,算子的重寫主要是適配 C++ 客戶端的輸入輸出,另外改造了 C++ 客戶端以便采樣算子的調(diào)用。
這也是他們最終的方案,這樣改造后的 Euler 雖然在訓(xùn)練耗時上仍然高于原生 Euler,但是差距控制在了二倍以內(nèi),符合預(yù)期。
當(dāng)談到本次有什么值得圖學(xué)習(xí)興趣小隊留意的項目時,隊長楊鑫表示比較關(guān)注的是大油條東北虎隊伍的項目——如何吊打 Nebula 的深度查詢,這個項目的優(yōu)化思路對他們很有借鑒意義。
因為在實際使用中,圖興趣小隊所在團隊的業(yè)務(wù)方有很多的多跳查詢需求,包括 GO 查詢、FINDPATH 查詢等。這本應(yīng)該是 Nebula Graph 所擅長的部分,在大部分場景下也確實如此,但是在遇到出度很大的頂點的時候,查詢性能會急劇惡化。其主要原因還是基于目前 Nebula Graph 的架構(gòu),多跳查詢只能先將一跳的結(jié)果集匯總到 Graph 服務(wù)后才能進行下一跳計算,完全不能將多跳計算下推。而這個項目正好給他們提供了一個解決這個難題的思路。
[免責(zé)聲明]
原文標(biāo)題: 基于 Nebula Graph 構(gòu)建圖學(xué)習(xí)能力
本文由作者原創(chuàng)發(fā)布于36氪企服點評;未經(jīng)許可,禁止轉(zhuǎn)載。




















