流批一體架構的必要性 | 滴普科技FastData系列解讀

上篇文章講解了大數據流處理架構的技術迭代與演變歷程,重點提到Lambda架構。但此架構相當復雜,整體存在三大特點:其一,流處理(speed)和批(batch)處理兩套代碼;其二,batch 與 speed存在計算結果不一致的情況;其三,兩套技術棧,增加運維工作量。而Kappa架構則可以很好地解決Lambda存在的問題,實現了技術棧以及業務代碼的統一,但也帶來一些新問題。
1. Kappa架構面臨的新問題
1.1數據重處理(re-processing data)
比較常見的情況是,處理算法或者Schema發生了變化,或者修了一個bug,這種情況下都需要把新版本的作業重新跑一遍,以獲得正確的結果。若只是重跑幾天的數據,也不是個大問題。但如果需要重新運行一年的數據,問題就會變得復雜起來。
1.2數據亂序
這一問題在移動App和IoT場景中常見,主要原因是網絡延遲或者中斷導致數據被延遲送達。如何處理這些遲到的數據,是Kappa架構要解決的問題。
1.3計算成本增加
流式計算相比批計算,雖然開發、維護成本和存儲成本降低了,但是可能會占用更多的計算資源,導致計算成本的增加。
1.4 難以支持復雜join
少量的join操作通常不會產生問題,但如果join的維度表數量增加到幾十個的時候,使用Kappa就會讓開發變得異常復雜。
總體上來說,Kappa架構也不是銀彈,無法粗野照搬,必須重新思考業務數據邏輯,結合周邊技術架構等實際情況來分析和解決Kappa帶來的新問題。
2. Kappa架構新問題的解決辦法
結合上節Kappa架構的問題,可以從架構內部、外部兩個方面分析和解決問題。Kappa架構的核心特征是事件驅動與實時,盡管周邊模塊會采用更適合自己的批處理模式或者其他編程模式去處理這些事件,并不一定強求使用流式處理。
在Kappa架構實踐中,通常使用Apache Kafka作為核心部件實現。接下來,可以看一下Kafka社區如何解決這些問題的:
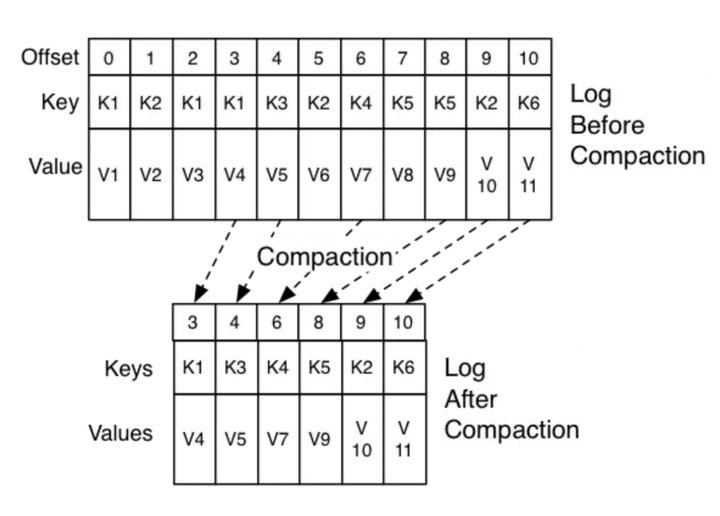
2.1 數據保留(retention):Compacted Topics, Tiered Storage
為解決數據重處理問題,Kafka需要支持時間跨度長的歷史事件的回放,其實就是log的存儲問題。目前,社區有Topic合并方案(Compacted Topics)和Tiered Storage方案。其中,Tiered Storage被認為是顛覆性的,可惜離發布還有一段時間,大家可參考KIP-405
2.2 數據一致性和可靠性: Exactly-once semantics
流處理引擎需要支持精確一次(Exactly-once)語義保證數據最終一致,同時在集群可控性上,需要支持跨數據中心的集群管理與數據同步。
2.3 處理遲到(late-arriving)數據
流處理引擎(Kafka官方提供了confluent流處理方案)需要完善的狀態管理以及配套的Sink,包括重新加載和重放事件的能力。當然,除了Kafka配套的流處理引擎,其他引擎也可以與Kafka一起使用,如Apache Flink。
2.4 數據重處理(backfill)
數據重處理對Kafka集群的計算資源的要求是很高的,靈活的資源管理與調度系統是很有必要的。
2.5 Kappa架構的擴展模塊
Kappa架構是以流式處理為基礎的,但也不意味著靠一個流處理平臺就能包打天下,還需要其他工具或數據庫的配合,以共同解決相關的問題。使用合適的工具干合適的事情。例如,復雜SQL需要其他SQL引擎甚至數據庫處理。特別是由于Kafka集群管理功能現有的限制,更需要其他工具來配合完成。
到目前為止,我們簡單描述了Kappa架構“內核”需要具備的能力,以及Kafka作為內核之一要解決的問題及技術方案。
擴展模塊包括應用、數據存儲以及分析平臺:
- 數據消費組件: 從流處理平臺消費數據,需要支持不同類型的消費速率,實時、近實時和批量。
- 存儲組件: 內置或者通過社區提供不同的存儲組件(內存數據庫、關系數據庫、NoSQL等)Sink連接器,并且根據業務要求,需要支持流式接口(changelog)或者批量接口。
- 數據處理: Kappa流處理平臺需要支持各種流應用,需要指出的是,對于計算資源要求特別多的工作負載,可能還是需要求助批處理引擎。Flink提供流式處理和批處理兩種模式,可以滿足不同工作負載的需要。
基于與多個同行的交流,實時流式普遍有需求,而且認為Kappa架構在架構上優于Lambda架構。然而,實踐中部署Kappa架構在國內還是比較少。
造成這種叫好不叫座的局面,這里存在技術推廣周期的因素,但也有技術問題未解決,有兩個原因:其一,在缺少長遠規劃的前提下,在批處理基礎上加上流處理的應用快速推出流式應用,這是比較保險的做法;其二,Kafka在這個解決方案中也存在相關未解決的問題。
3. Kappa架構的擴展性與成本
本文接下來的篇幅就著重描述它的幾個重要問題,以及我們的一些觀點。
3.1 擴展性與成本問題
將大規模的數據保存到Kafka中是有很大問題的,在PB級的時候存在成本與可擴展性問題:
在存儲成本方面,與數據湖方案或者私有化環境上的HDFS都差很多,特別是在公有云上,云服務提供商(例如AWS S3,阿里OSS)提供的對象存儲方案成本優勢非常明顯,估計成本相差5倍以上;
Kafka在存儲擴展方面也是非常繁瑣,這里的技術原因是當前版本的存儲與計算是耦合的。
上文提到過采用Topic Compaction的方法壓縮數據,從而減少存儲空間。但此方法限制比較大,且在擴展能力方面無法滿足要求,因為大部分人希望的是instant elastic能力,現有的擴容機制在數據量大的時候需要等待很長時間,這個期間系統可能無法提供服務,流計算對此通常是無法容忍的。
為了徹底解決上述問題,Kafka社區也在抓緊開發Tiered Storage特性。Tiered Storage采用存儲與計算分離的架構,社區對這個特性非常期待。需要指出的是,Kafka的競品Pulsar已經實現了存算分離,但為什么Kappa架構沒有真正流行起來呢?也許還有其他原因。
3.2 需要更多計算資源
這個問題的本質是流式計算引起的,也是為“實時”付出的代價。然而,在企業中并不是所有的業務都是需要實時處理的。
合適的工具干合適的活,下面這個圖來自Uber,該方案把Kappa的使用局限在數據集成部分,這在一定程度上解決了計算資源的問題,同時也是一種架構演進的思路。
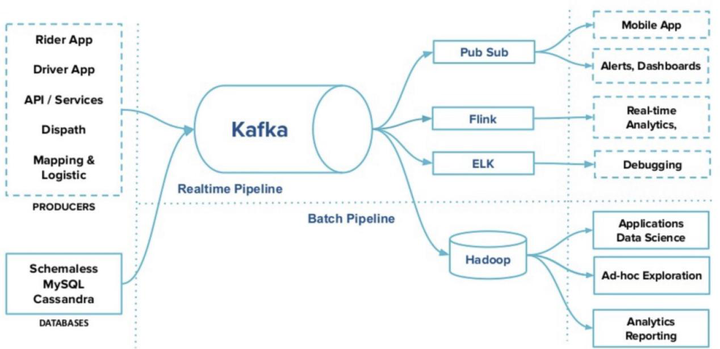
雖然業界也在解決Kappa架構中Kafka固有的一些問題,但在實踐中,大部分人把Kappa的實現局限在數據集成這一環節的。導致這一結果的原因就是所謂天下沒有免費的午餐,所有環節使用流處理是不切實際的,畢竟流式計算需要的計算資源會比較多。
因此,使用流批一體的計算引擎綜合兩種不同業務需求,是比較自然的做法。滴普科技構建的一站式云原生數據智能平臺Fastdata,在流批一體相關功能特性上已經做了嘗試,關于流批一體的具體方案我們在后續的文章中展現給大家。












