大數據流處理架構 | 滴普科技FastData系列解讀

在大數據技術發展早期,離線計算(批處理)作為唯一的大數據處理技術,很快在各個場景下取得了驚人成果,吸引了一大批優秀的科學家和工程師,這些因素的疊加使大數據技術快速成熟,形成了以HDFS+YARN+Spark為格局的Hadoop生態體系。
同時,離線計算也成為了大數據的主流技術,但在由Hadoop構筑的離線計算大廈上空,卻也飄著幾朵烏云,其中一朵就是高延遲。
Hadoop在設計之初便確定了架構目標:高吞吐、高容錯、易擴展。而高吞吐和低延遲又在一定程度上對立,因此早期Hadoop在架構上就決定了其高延遲的缺陷,這直接限制了離線計算的使用場景。
而Storm、Spark Stream、Flink等大數據流處理框架的普及,對大數據技術早期的批處理計算邏輯帶來了顛覆,解決了高延遲的問題,極大地擴充了大數據處理的使用場景,將大數據處理帶到了一個全新的實時計算時代。實時計算的普及再一次推動著技術的進步和人們認知的提升,一些之前離線計算無法解決的低延遲場景開始迅速被實時計算所解決。
然而,在實際情況中,受限于資源性能的因素,很多問題往往需要輔助一些歷史數據,因此并不能直接通過實時計算完成。在這些場景下,就要求實時計算需要配合離線計算共同完成某些任務。在這樣的背景下,融合離線計算和實時計算的流處理框架應運而生。
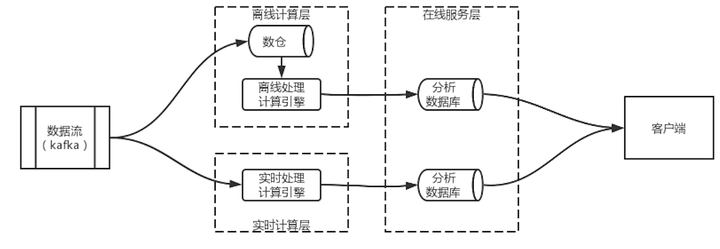
上圖展示了一個Lambda架構的示意圖,Lambda架構分為實時計算層、離線計算層和在線服務層。其核心思想是事件在被實時計算引擎處理的同時寫入到離線計算的存儲中,并于在線服務層中合并,得出最終結論。
2.1 離線計算層
離線處理層用于將事件持久化存儲到數倉中,并對數倉中的歷史數據進行批量計算,將結果保存到分析數據庫中。分析數據庫不同于持久化的數倉,需要配合實時計算,因此延時必須要低,所以最好選擇一些查詢速度快的分析型數據庫,例如Clickhouse、Elasticsearch等。
2.2 實時計算層
實時計算層在有些文獻中也被成為快速處理層,本質上就是用于處理流式數據。這一層的主要職責是提供低延遲的實時計算能力,但由于其能力有限,一般用戶計算一個小的時間窗口的增量數據。得出的增量數據會被推送到分析數據庫中,或直接觸發在線服務層的業務,從而實現實時處理。
2.3 在線服務層
在線服務層可以是業務系統,主要承擔合并離線計算和實時計算結果并觸發下游業務動作的職責。理論上離線計算得出的歷史數據+實時計算得出的增量數據=真實的實時數據。
2.4 案例:智能補貨
讀者們可以考慮一個門店零售中的智能配補貨場景:某連鎖品牌鞋店,新上了一批鞋子,需要實時監測鞋子的銷售情況,并在合適時機觸發補貨機制。我們假設一條規則:某個尺碼庫存數量-過去三個月該尺碼日均銷量≤1時,觸發補貨。
在這個場景中,可以將計算分成實時和離線兩部分:
離線部分負責每天凌晨統計所有門店過去3個月的銷售情況,并將結果寫入離線計算的分析數據庫中;
實時計算部分負責實時監測當天門店內各個尺碼鞋子的庫存,將每個銷售事件推送到在線處理層;
在線處理層負責接收實時計算層的事件,并讀取離線計算的分析數據庫來判斷規則,最終確定是否需要觸發補貨機制。
這一案例的規則非常簡單,真實世界中的規則會更復雜,但已經能夠說明Lambda架構是如何解決需要同時依賴離線計算和實時計算問題的場景。
2.5 Lambda架構總結
Lambda架構的核心邏輯在于,它認為真實結果=增量結果+歷史結果。因此,其設計了三個獨立的計算層,分別用于計算增量結果、計算歷史結果、處理兩者的合并。這種架構在很大程度上解決了當數據量太多無法全部實時計算的缺陷。
同時,由于實時計算和離線計算使用兩套計算引擎,兩套計算引擎的API和抽象都不同,因此原始的Lambda架構也存在著使用和維護難的問題。
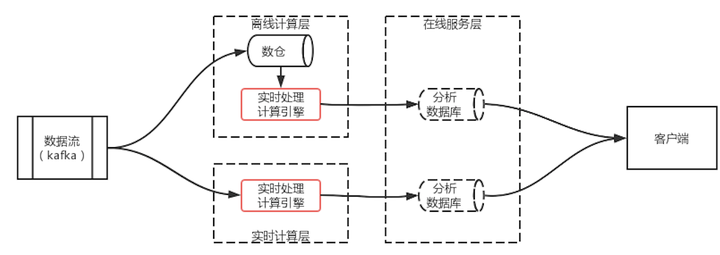
Kappa架構本質上是Lambda的一個變體,目的是為了解決Lambda架構中兩套不同的計算引擎導致的使用和維護難的問題。
如圖 2 Kappa架構示意圖所示,Kappa架構的核心是將兩套計算引擎合并成一套。換句話說,要么使用批處理的計算引擎來計算流,要么使用流處理計算引擎來處理離線問題。
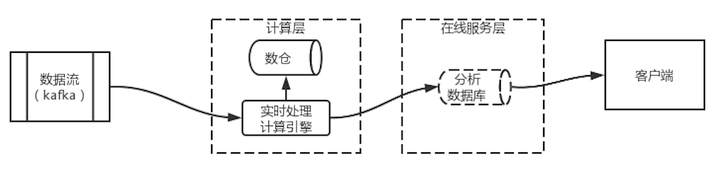
圖 2 Kappa架構示意圖的架構可以簡化成圖 3 Kappa架構圖中的架構。數據流進入實時處理計算引擎,由實時計算引擎進行運算,將結果保存到分析數據庫中,同時將原始數據保存到數倉中。在這一架構中,數倉可以使用對象存儲引擎來代替,保存所有歷史數據。同時,分析數據庫也變為可選。
3.1 極端的Kappa
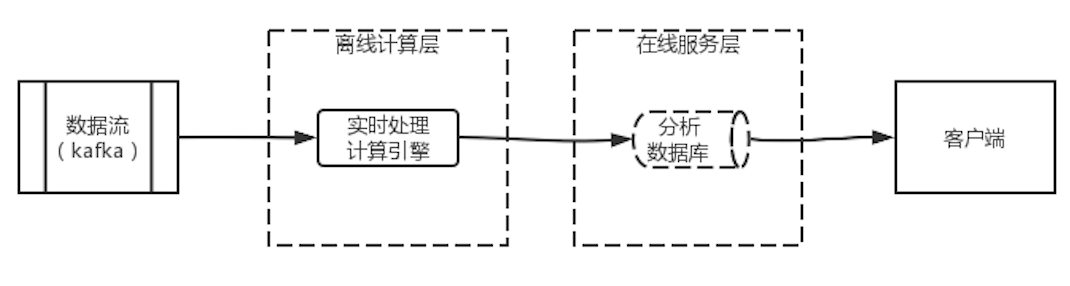
Kappa架構的實際使用中,也有部分企業使用了另一個更極端的Kappa架構的變體。架構圖如圖 4 Kappa架構變體所示,該變體完全拋棄了數倉,將所有數據都保存在Kafka中。當需要計算歷史數據時,對Kafka進行數據重放即可。
這種架構完全拋棄了離線計算,能夠降低架構復雜度和維護工作量,但并不適用于所有場景。主要原因在于,此架構在計算歷史數據時需要對kafka數據進行重放,而重放的計算效率比較低,會消耗大量的計算資源和時間。因此,若業務需要對歷史數據進行計算,就不適合應用本架構。本架構中對歷史數據的計算更多的用于偶發錯誤的糾偏,而不適用于周期或頻繁的業務數據計算的場景中。
Kappa可以看成lambda架構的變體。那么為何Lambda架構提出時,沒有將兩套引擎合并成一個呢?
Lambda架構是由Storm的發起者、Twitter工程師Nathan Marz提出。在實時處理的前期,只有Storm一套實時計算平臺,人們對實時計算的認知還處在早期,大家普遍認為實時計算和離線計算就是涇渭分明的兩種計算方式。直到Storm Trident的推出,第一次提出了微批的概念,將流計算認為是批處理的特例,因此可以使用批處理的方式來處理流數據。而到了2013年Spark stream的推出,才真正將流處理和批處理都統一到了Spark中。
使用微批處理流數據的優點顯而易見,可以將離線和實時統一到一套計算引擎中,這為Kappa的興起帶來了契機,但同時,微批處理的方式也造成了延遲高的缺陷。
而隨著人們認知的提升,Flink再次顛覆了人們的認知。與微批思路的不同,Flink將批處理視為流處理的特例,因此只需要實現流處理即可。于是,Flink橫空出世,更進一步降低了實時處理的延遲。
縱觀流處理的歷史,不難發現人們認知的改變帶來了技術的變革。在Lambda架構提出的時候,流處理和批處理尚未統一,因此也不難理解為何當時需要設計兩套計算引擎。當然,人們認知的改變也并不一定是先進的,即使到現在,Lambda架構依然有著非常大量的使用場景。造成這個現象的主要原因,在于技術的發展并沒有能夠實現一套架構處理所有問題。目前的流處理技術,對于大數據量的歷史數據的處理,還是非常吃力的。
這就對架構師提出了更高要求,一招鮮吃遍天并不適用于架構領域。“沒有銀彈”這句話在流處理的歷史中也頻繁展現其威力,那么,作為架構師我們應該如何應對這種挑戰呢?
我認為,需要用洞察的視角透過現象看本質。放到本文中,我們再次回到文章開始提到的:在由Hadoop構筑的離線計算大廈上空,卻也飄著幾朵烏云,其中一朵就是高延遲讓我們用洞察的視角再來觀看整個流處理的歷史進程。
4.1 低延遲與高吞吐的矛盾
文章開頭提到了Hadoop設計之初的設計目標是高吞吐、高容錯、易擴展。在數據處理領域,高吞吐和低延遲是矛盾的,因此Hadoop在設計之初就無法支持低延遲的實時處理場景。Storm被發明出來解決這個問題,Storm通過全新的架構設計支持了低延遲,但同時也沒有逃脫低延遲與高吞吐的矛盾,低吞吐也就成為了Storm的一個缺陷。
微批處理方案的出現,將流數據視為一系列非常小的批組成的集合,一次處理一個微批。這種方案在一定程度上改善了吞吐率。但也在實時性上帶來了一些問題,因此其延遲相比較于Storm會變高。
Flink將批數據視為流數據的特例,因此其采用流處理引擎來處理批數據。這也為Flink帶來了低延遲的特性,并且由于其具備了處理批數據的能力,因此其吞吐量獲得了一定的提高。但看似實現了低延遲和高吞吐同時滿足的情況,這其實只是相比較而言的,面對真正的大數據量而言,Flink依舊無能無力,因此在很多場景下依然需要Lambda架構。
其實,無論是Lambda架構還是Kappa架構,本質上就是低延遲和高吞吐之間的選擇。在有些場景下,追求低延遲并不需要高吞吐,這種場景就可以選擇Kappa架構,其他場景就需要選擇Lambda架構。
本文向讀者介紹了流處理產生的背景及兩種常用的流處理架構,同時向讀者剖析了兩種架構的本質——低延遲和高吞吐的矛盾,這為讀者在未來選擇何種架構提供了理論指導。
最后,Kappa架構本質上是一個流批一體架構,關于流批一體更詳細的內容,請關注下期專題文章。












