2022斯坦福AI指數報告出爐!中國霸榜AI頂會,但引用量最低

【新智元導讀】2022年人工智能指數報告發布了!這份報告中,中國在AI頂會論文上表現不凡,但在引用數量方面卻低于美國、歐盟和英國。
今天,斯坦福大學發布了2022年人工智能指數報告。
李飛飛教授在報告發布后第一時間轉發。

今年的報告主要分為5大章節:研究及發展,技術表現,人工智能應用的道德挑戰,經濟和教育,人工智能政策和國家戰略。
以下將為你提取7項報告要點:
過去的10年,全球AI論文發表量實現翻番,從2010年的162444篇增長到334497篇,且逐年遞增。
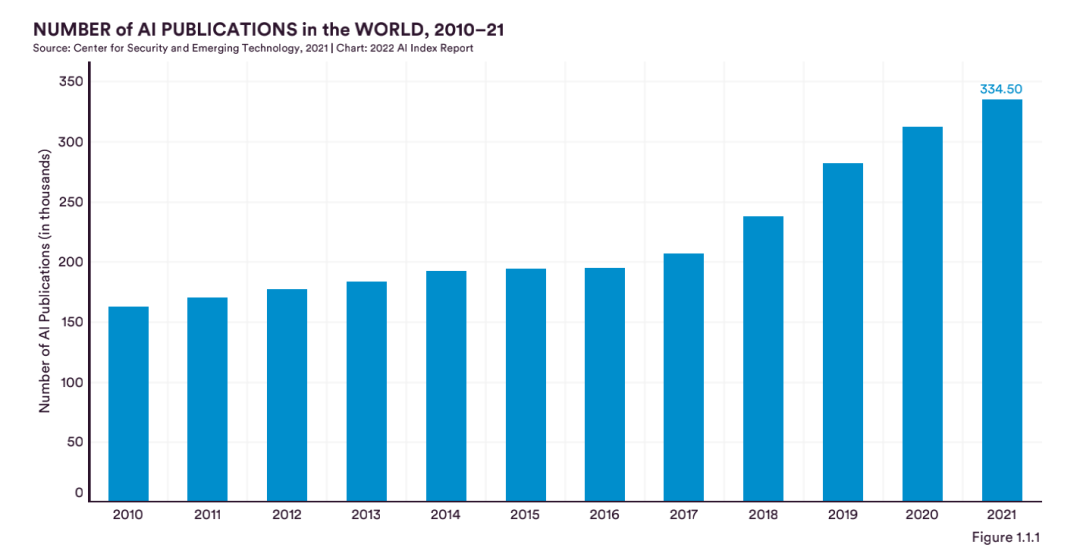
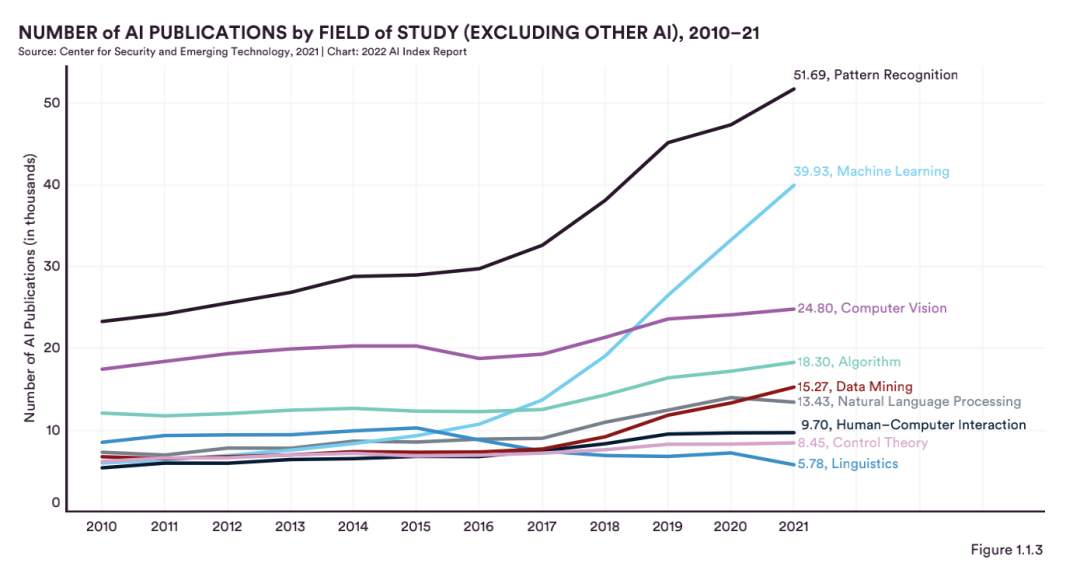
具體而言,模式識別和機器學習領域的論文,僅2015年至2021年的6年間,就實現了倍增,其它諸如計算機視覺、數據挖掘和自然語言處理等領域,保持了比較平穩的發展。
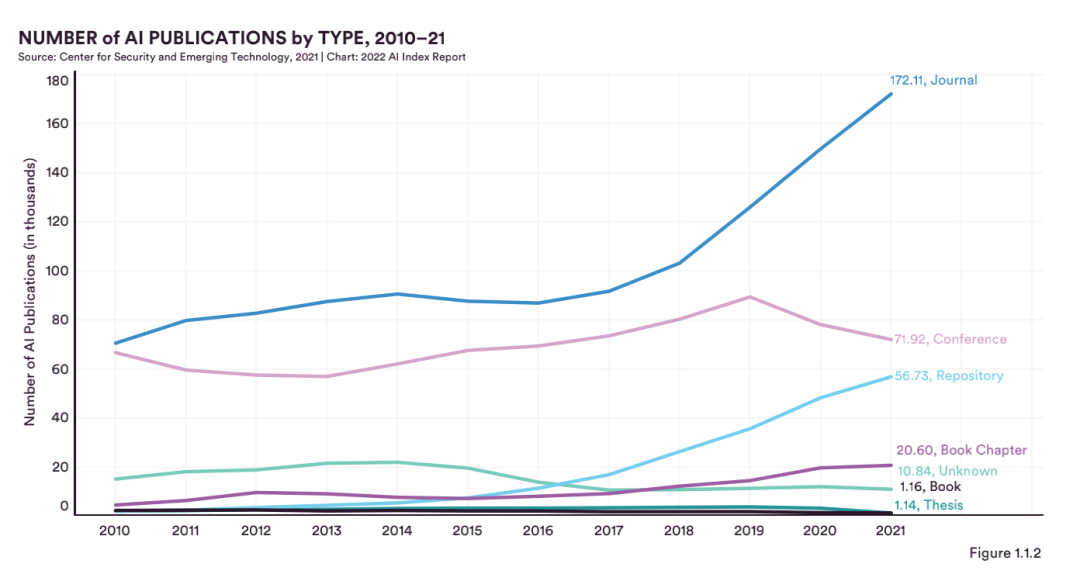
另外,從論文的刊載情況來看,期刊文章占比最大,51.5%;21.5%是頂會論文,17.0%來自存儲庫。
可以看出,在過去12年中,期刊和儲存庫的論文分別增長了2.5倍和30倍,但頂會論文的數量自2018年以來有所下降。
論文跨國合作來看,從2010年到2021年,中國和美國共同發表的人工智能論文數量全球最多,自2010年以來就增加了5倍。中美合作的出版物數量是中英的2.7,世界排名第二。
2021年,中國在人工智能期刊、頂會和知識庫出版物的數量上繼續領先世界。這三種出版物類型的總和比美國高出63.2%。
與此同時,美國在人工智能頂會論文數量和存儲庫引用的數量上處于領先地位。
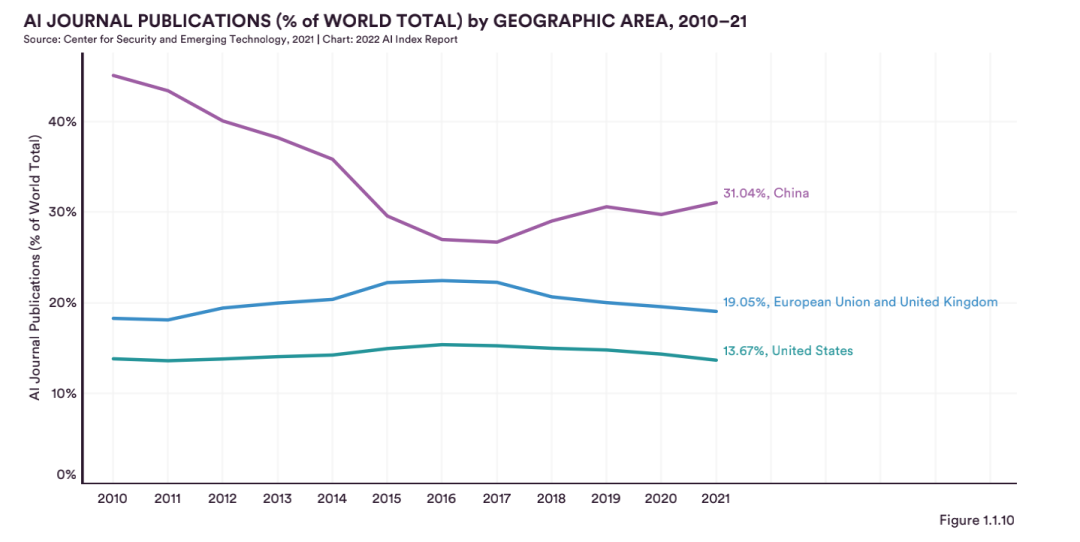
就AI期刊論文發表數量來看,過去12年人工智能期刊論文發表數量占比,中國始終霸榜,2021年為31.0%(2020年占比18.0%),其次是歐盟和英國,為19.1%,美國為13.7%。
2021年,中國在AI期刊的全球引用量依舊領先。
值得注意的是,不論是AI期刊論文發表數量、引用數量,美國從去年第2名降至第3名。

那么中美在頂會發表論文的情況如何?
2021年,中國以27.6%的比例在全球AI頂會發表的論文數所占份額最大,比2020年的領先優勢更大,而歐盟和英國以19.0%緊隨其后,美國以16.9%位居第3。
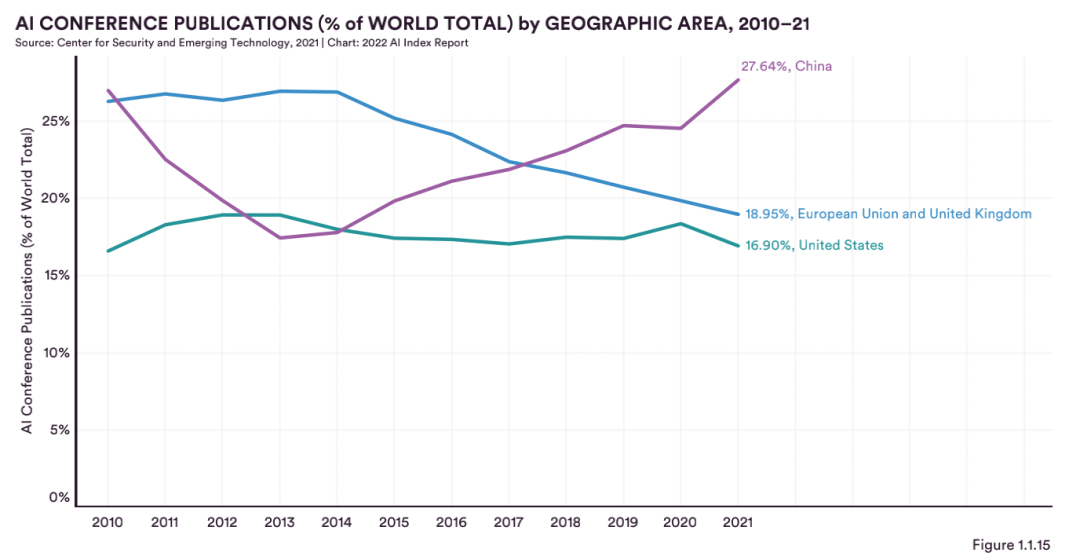
然而,美國一直在AI頂會論文引用量上居高不下,2021年引用總量占比29.52%,排名第2和第3的分別是歐盟英國(23.32%)和中國(15.32%)。
中國從去年第2名跌倒第3名,從側面可以看出,中國論文發表數量最多,但質量不如美國高。

總體來看,2021年人工智能專利申請量是2015年的30多倍,年復合增長率為76.9%。
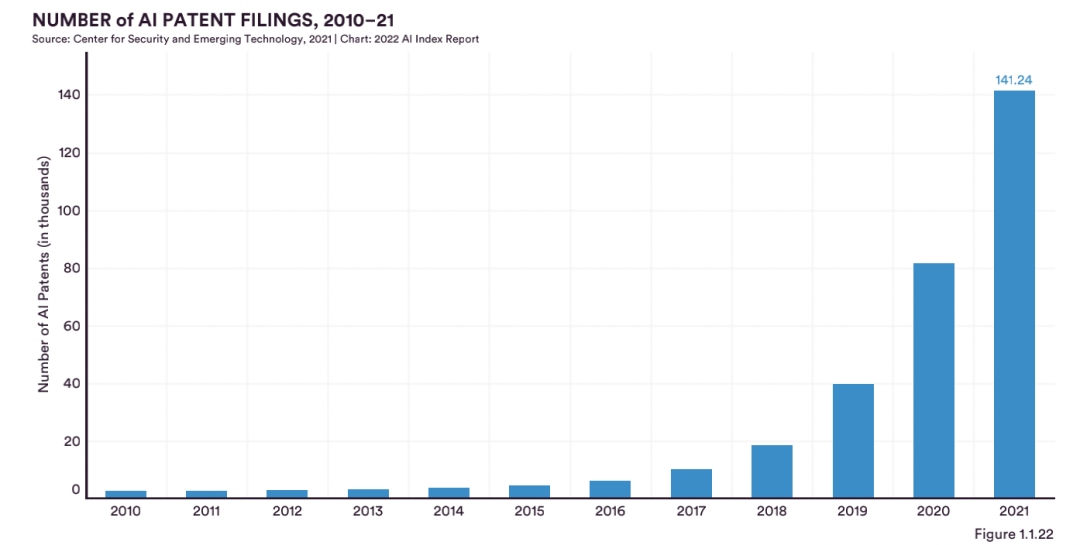
具體講,中國申請了全球一半以上的AI專利,并獲得了約6%的授權,與歐盟和英國大致相同。
與不斷增長的人工智能專利申請和授權數量相比,中國的專利申請數量(2021年為87343件)遠高于授權數量(2021年為1407件)。
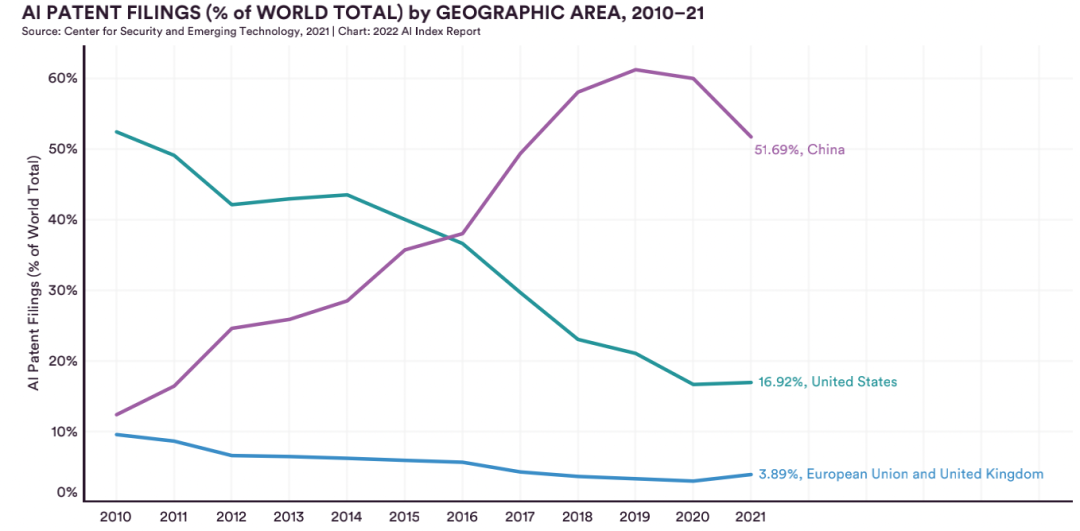
最受歡迎GitHub開源庫:TensorFlow
從2015年至2021年GitHub開源AI軟件庫的用戶數量可以看出,TensorFlow仍然是2021年最受歡迎的,GitHub累計星數約為161,000,比2020年略有增加。
排在第2名的便是OpenCV,緊隨其后的是Keras、PyTorch 和 Scikit-learn
先來看一組照片,這展示了人臉生成水平的年序發展。

對比2014年,我們僅能將原本膚色表情豐富的真人,生成一張黑白且模糊的人臉,但是到了2021年,計算機對黑色皮膚也能揭示更多細節,我們看到了圖像人物皮膚的黑里帶棕,以及表情的露齒帶笑。
報告展示了計算機圖像如何分類,下圖包括飛機、自動汽車、鳥、貓、鹿、狗、青蛙、馬、船、卡車等各種類別,通過給定圖像的分類模型與目標標簽,提高了圖像識別的智能化程度。

報告指出,隨著深度學習運用于AI圖像,圖像分類的準確性有了很大提升。
以下是AI圖像識別準確性的對比圖,藍色線條代表沒有使用訓練數據,綠色線條代表使用了訓練數據。很明顯,綠色線條(準確率99.02%)超越了藍色線條(準確率97.9%),這意味著,AI圖像識別經數據訓練后準確性提高。
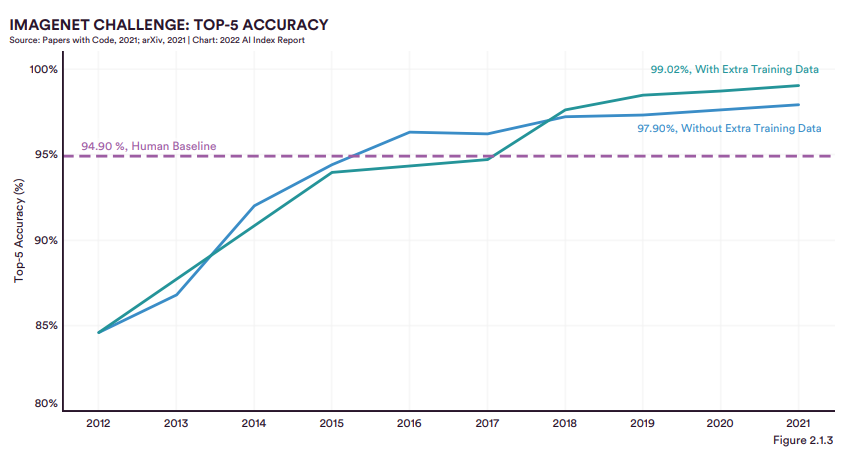
而無論是否使用深訓練數據,AI圖像分類(99.02%&97.90%)在2017年后均表現出了高于常人(94.9%準確率)的水平。
看來,「臉盲癥」只存在于人類,AI幾乎不會患。
報告使用了一份來自北京郵電大學的口罩人臉圖片集,這6000個人臉識別數據集,提升了疫情期間人臉識別的準確率。

口罩遮擋住面部,這使得人臉識別系統收集到的面部信息大量減少,然而,來自中國的AI團隊將人臉識別的關鍵信息集中于眉毛和眼睛,并采用正確的模型進行訓練,實現了「戴著口罩也能刷臉」。
來看一下,計算機如何進行視覺常識推理的。

視覺常識推理,Visual Commonsense Reasoning(VCR)是AI領域的前沿熱點問題,這是一項非常富有挑戰的任務,包括認知、學習、推理,從單一的視覺問答、圖像識別、動作捕捉等數據處理,上升到「跨媒體智能」,代表了計算機視覺理解的新基準。
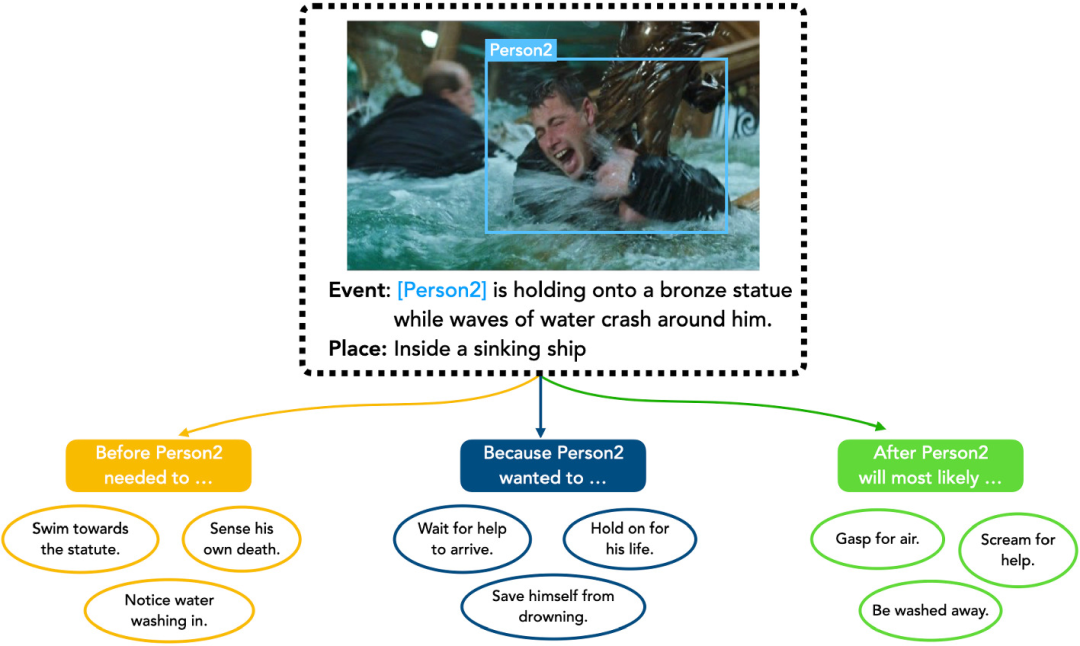
報告指出,目前,計算機視覺常識推理能力遠遠落后于人類,人類的視覺常識推理水平一直維持在85分,而2021年機器的最佳得分只有72分。
看來,這確實有點Low,不過相較于2018年的不及格水平(43分),機器用3年時間提高了29分,顯然是在大步向前了。
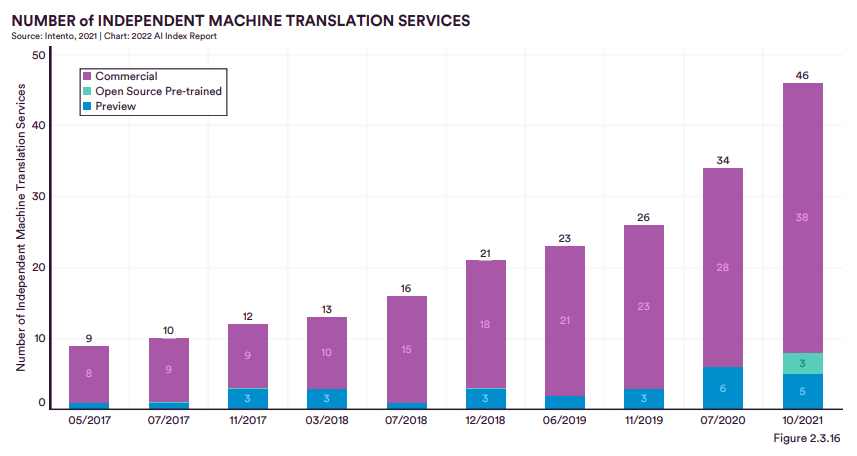
近年來,得益于語音識別技術的發展,完全機器翻譯的服務應用大幅提升,占比46%。
相較于其它的應用,機器翻譯的商業應用增速明顯,商用規模從2019年的21%擴大到2021年的38%,近2倍。
報告使用了2015年由斯坦福大學Bowman等人提供的自然語言處理的問題和標簽。

自然語言處理是在給定確定任務的前提下,假設4種邏輯,即錯誤(contradiction矛盾)、未決定(neutral中性)2種、是否為真(entailment蘊涵),機器對進行合理與不合理的推論。
報告顯示,2021年自然語言處理的精準度已達93.1%,而在2017年初就已經達到90%,這是在高起點的基礎上實現緩增長。
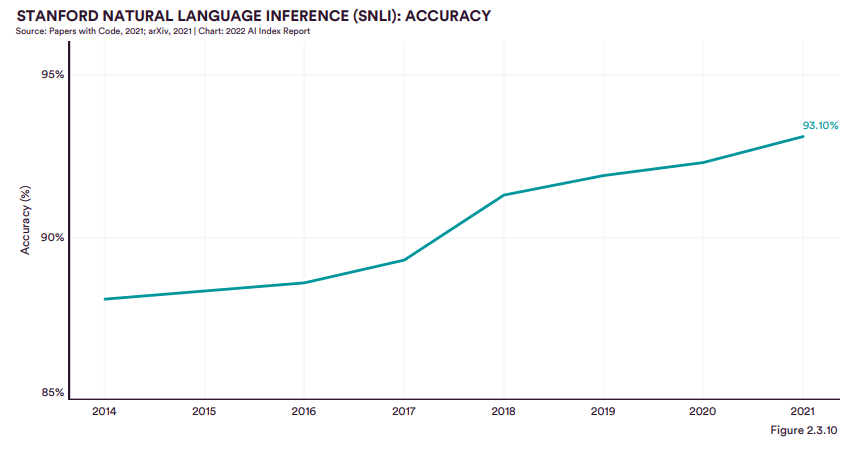
斯坦福自然語言推理(SNLI)數據集包含約60萬對被標記的句子,其性能精度是基于答對問題的百分比。
從今年報告的總體體量上而言,較之于去年的7章,今年報告濃縮至5章,減少了「AI的多樣性」部分,并將「AI經濟」和「AI教育」合為「經濟和教育」1章。

雖然總章數減少了,但是體量卻變大了,目錄頁碼由177頁增加到了196頁。
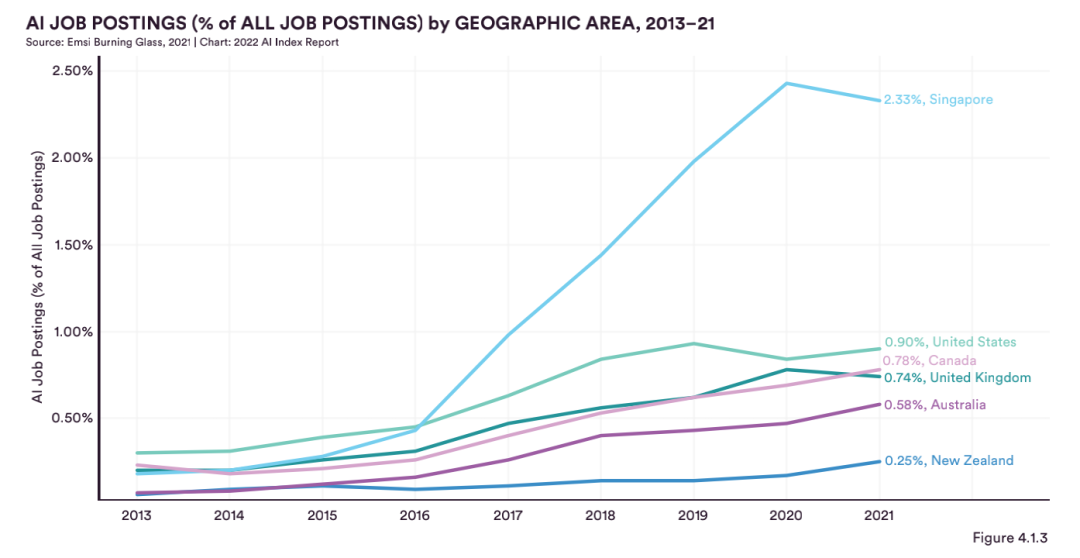
Burning Glass數據涵蓋的六個國家對人工智能勞動力的需求在過去九年中顯著增長。其中新加坡AI招聘崗位在總招聘崗位中占比2.33%,排名第一,美國0.90%排名第二。
就人工智能領域投資來講,從2013年到2021年,美國對人工智能公司的私人投資是中國的2倍多。
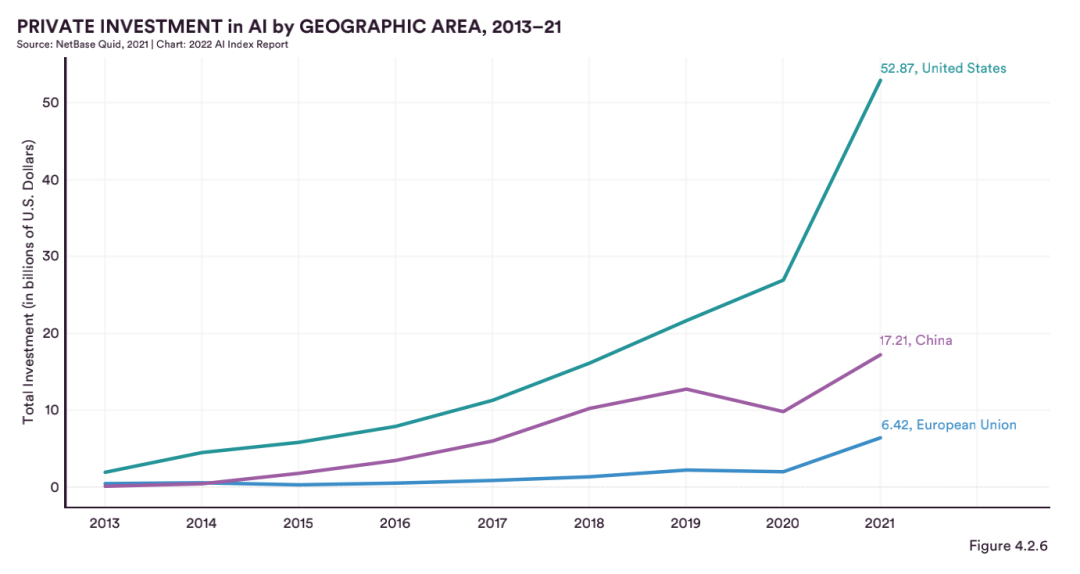
中國的AI投資出現了增長,從2020年的10%上升到了2021年的17.21%。
報告下載地址:
https://aiindex.stanford.edu/wp-content/uploads/2022/03/2022-AI-Index-Report_Master.pdf
本文來自微信公眾號“新智元”(ID:AI_era),36氪經授權發布。





















