聊一聊圖數(shù)據(jù)庫應用的現(xiàn)狀和 NebulaGraph 未來發(fā)展|NUC 2022

歡迎,今天到場的各位嘉賓。
去年的 NUC 大會我大概介紹了一下圖數(shù)據(jù)庫的發(fā)展歷程以及 NebulaGraph 的產(chǎn)品情況,今年大會的主題是 The future of the big data——大數(shù)據(jù)的未來,所以想花十幾分鐘時間分享下我這段時間在圖數(shù)據(jù)庫未來方向上的一些想法。
今天報名的觀眾大多數(shù)都是 NebulaGraph 的用戶,大家應該差不多都是在這兩三年,最多三四年里開始接觸和使用圖數(shù)據(jù)庫的,其實整個國內(nèi)基本也是這樣一個趨勢。國內(nèi)的投資機構、圖數(shù)據(jù)庫新興企業(yè),基本上也是在過去三四年的時間里,像雨后春筍一樣興起的。
這幾年, NebulaGraph 的實名用戶增長速度也非常快。這里可以分享個數(shù)據(jù)——從 2021 年的第一季度到目前,NebulaGraph 整個的實名用戶的差不多是 6 倍多的增長。這不光說明了大家對我們產(chǎn)品的認可,也反映了圖數(shù)據(jù)庫市場正在走向成熟。
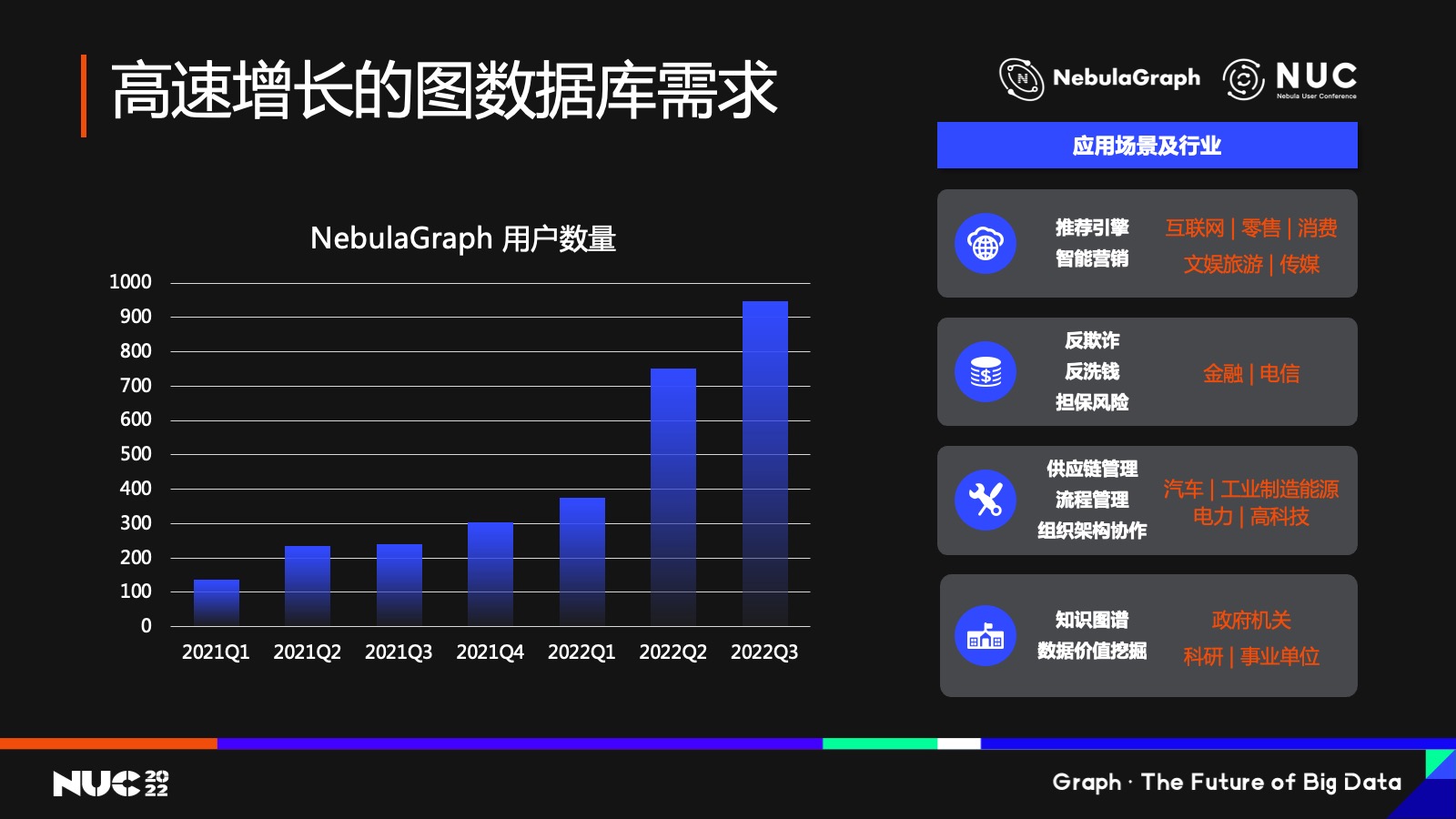
與此同時,越來越多商業(yè)化用戶需求在不斷冒出來。右邊就是我們觀察到的,目前圖數(shù)據(jù)庫需求比較旺盛的領域。
從最早的互聯(lián)網(wǎng)企業(yè)的社交圖譜應用,發(fā)展到推薦、風控等領域。然后就是金融行業(yè),包括銀行、證券、期貨、保險等企業(yè),我們把電信運營商也包含了在這里面。這些企業(yè)對圖數(shù)據(jù)庫的需求也是差不多在過去的 3-4 年逐漸起來的,而且逐漸變得成熟,我們看到圖數(shù)據(jù)庫的需求進入正逐漸進入這些企業(yè)的業(yè)務主鏈路,應用在比如反欺詐、反洗錢、反騙保、投研分析等等領域。
第三個領域其實非常有意思,是高端制造。從去年開始我們接觸很多這個領域的用戶,在這里有汽車制造,有高端電子產(chǎn)品制造等等,我們把電力能源部門也歸在了這一類里面。這一類企業(yè)對圖數(shù)據(jù)庫的需求來自于,例如供應鏈的管理,生產(chǎn)流程管理,產(chǎn)品維修管理,用戶管理等等一整套的流程管理,所以說增長速度還是非常快的。
那么大家可能會問,供應鏈管理這個話題已經(jīng)比較老了,我記得最早是在上個世紀 90年代出現(xiàn)的,也就差不多 20 多年前出現(xiàn)了,為什么現(xiàn)在又有?其實之前的供應鏈管理可能比較簡單,就是管理供應商——他們提供了哪些批次、哪些原材料,那么這種管理的數(shù)據(jù)量其實很小。現(xiàn)在隨著技術的不斷前進,供應鏈管理的重心開始發(fā)生變化,或者說從供應端開始轉向了消費端。
舉個例子,比如汽車制造,原來只是關心誰提供了輪胎,誰提供了引擎等等這樣一些部件,這個數(shù)據(jù)量其實不多;但如果需要追蹤每一輛汽車上、每一個零部件是由哪個廠家提供的呢?大家知道一輛汽車可能有幾萬甚至十幾萬零部件,那么大一點的汽車制造廠,一個月就可以生產(chǎn)十幾萬輛汽車對吧?如果說我們把每一輛汽車上的零部件,乘以一年生產(chǎn)的汽車總數(shù)量,如果追蹤到這樣細的粒度的話,這個數(shù)據(jù)量就非常驚人了。所以說我們看到業(yè)務的發(fā)展,正從原來的供應端開始向消費端在遷移,過程當中數(shù)據(jù)量暴增,這個時候就產(chǎn)生了對圖數(shù)據(jù)庫的一個必然的需求。
第四個領域是知識圖譜。幾十年前大家可能已經(jīng)知道有知識圖譜,但原來只支持一跳兩跳的關系查詢,現(xiàn)在會走得更深。比如做一些復雜的邏輯推理的時候,可能是需要往下走十幾步。原來知識圖譜的數(shù)據(jù)可能是存儲在傳統(tǒng)的關數(shù)據(jù)庫里,但是隨著數(shù)據(jù)量變大以及對關系查詢復雜度變高,傳統(tǒng)的關系型數(shù)據(jù)庫就搞不定了——在這種情況下,大家對圖數(shù)據(jù)庫的依賴就越來越強。
除此之外,我們還看到了圖數(shù)據(jù)庫在新藥研發(fā)、芯片設計、甚至 Web3 、數(shù)字貨幣、元宇宙等一些新興領域的應用開始出現(xiàn)。所以說,為什么我們說未來已來?因為這些技術其實都代表著未來,可能在未來三五年甚至十年出現(xiàn)的技術中,圖技術都有它的應用場景。
上面大家已經(jīng)看到,圖數(shù)據(jù)庫行業(yè)整個的發(fā)展非常快,那么在未來的 3-5 年時間里面,哪幾樣東西對圖數(shù)據(jù)庫的影響會比較大呢?我也分享下我的看法。
1. 推動圖數(shù)據(jù)庫行業(yè)標準化
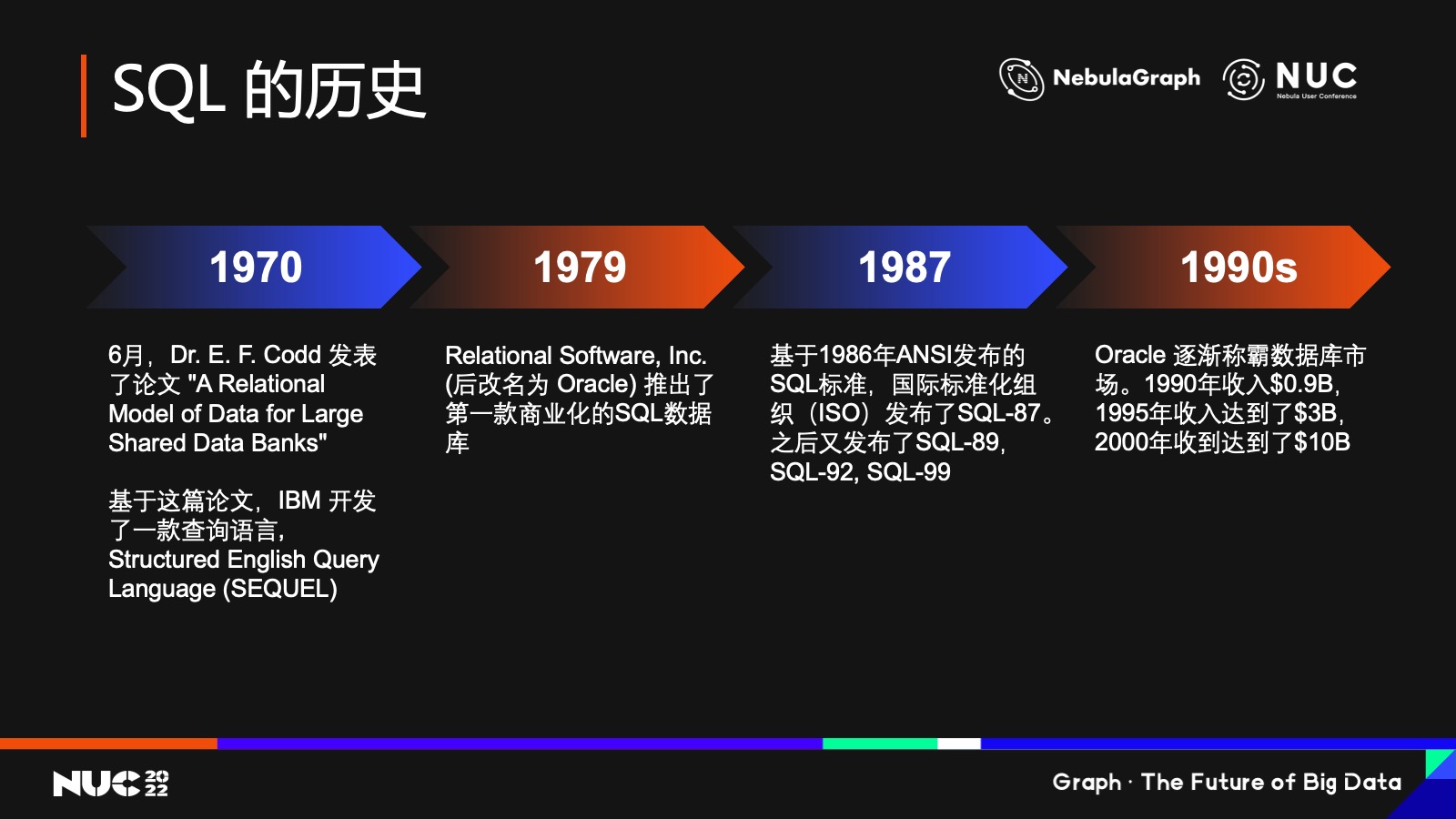
歷史總是重復上演,所以我們不妨先回顧一下關系型數(shù)據(jù)庫的標準查詢語言 SQL 的歷史——
1970年,Dr. E. F. Codd 博士發(fā)表了《A Relational Model of Data for Large Shared Data Banks》這篇論文,原來他們還不叫 Database,因為沒有 Database,當時他們稱為 “Data Banks”,其實就是現(xiàn)在的數(shù)據(jù)庫。論文里介紹了他們在大型數(shù)據(jù)庫里的一個關系模型,這就奠定了后來關系代數(shù)的基礎。
基于這篇論文, IBM 開發(fā)了一個查詢語言 —— 全稱叫 Structured English Query Language ,取首字母就是 SEQUEL。到了幾年后,大概 在 79 年之前,他們覺得SEQUEL 這個名字太長了,逐漸就把這個名字改成了 SQL,但發(fā)音還是一樣的。
這就是我們大家非常熟悉的,而且是目前整個數(shù)據(jù)業(yè)界唯一一個標準查詢語言 SQL 的來歷。79 年時,一家叫 Relational Software 的公司推出了第一款基于 SQL 的商業(yè)化數(shù)據(jù)庫;但大家知道這個時候 SQL 其實還沒有成為行業(yè)標準,只是 IBM 推出的一個查詢語言而已。而這家名叫 Relational Software 的公司,相信很多人都沒有聽過,就已經(jīng)推出了基于 SQL 的數(shù)據(jù)庫。但后來這家公司改了個名——Oracle,這個名字相信在座的各位就都聽說過了,對吧,就是后來的甲骨文公司。
關系型數(shù)據(jù)庫 在 80 年代的發(fā)展其實還是很慢的,到了 87 年,SQL 被 ANSI(美國國家標準局)接受為一個標準,有的人把它稱為 SQL-86,但這只是美國的一個標準,因為 ANSI 是美國的標準化組織;所以后來他們又通過國際標準化組織,就是 ISO,在 87 年時接納了基于 ANSI 86 的標準,推出了 87 年的 SQL 標準,業(yè)界把它稱為SQL-87。當然后續(xù)它還推出了很多版本,包括 89 年、92 年,到現(xiàn)在最新的,大家比較熟悉的 99 年版本。
那么,推出查詢語言標準的好處是什么?
第一個,各大院校開始開設數(shù)據(jù)庫這門課程了,因為他們可以用統(tǒng)一的標準來教授 SQL;第二從企業(yè)界來看,因為這有這樣一個標準,所以很多數(shù)據(jù)庫如雨后春筍一樣冒出來,大家都來支持 SQL。
那么剛剛說到的 Relational Software,就是后來的 Oracle,它是其中最大的受益者。因為這個標準的推出使得業(yè)界對數(shù)據(jù)庫的接受程度非常快。我們查了幾個數(shù)據(jù), Oracle是 86 年上市的公司,他們在 90 年的時候,全球總收入是 10 億美金不到,到了 95 年就已經(jīng)達到了 30 億美金,2000 年的時候就已經(jīng)達到了 100 億美金,10 年間有差不多10倍的增長,作為一個數(shù)據(jù)庫企業(yè)可以說是非常快了,當然這背后有很多原因,但其中一個很大的原因,我們認為是來自于這個標準。
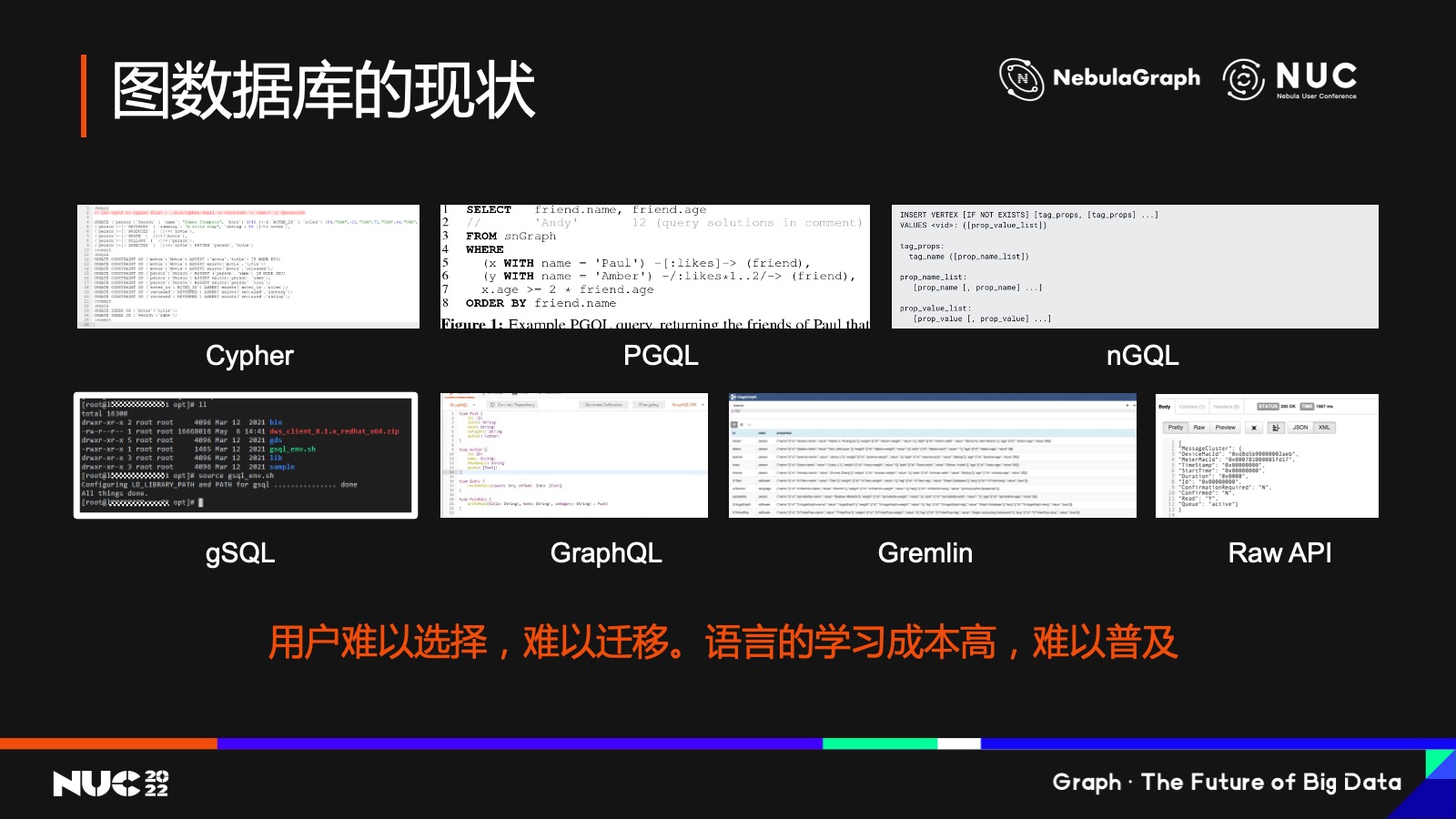
再回過頭來看一下圖數(shù)據(jù)庫的現(xiàn)狀。
現(xiàn)在的圖數(shù)據(jù)庫領域是一個比較分散的狀態(tài),光 query language 就有很多種,當然其中比較有名的或者說用戶量比較大的是 Cypher,這個大家知道是 neo4j 的查詢語言。然后還有 PGQ、以及 NebulaGraph 推出的 nGQL,我們也列在這里了。其他的還有 gSQL、GraphQL、Gremlin 等等。甚至還有一些圖數(shù)據(jù)庫,號稱支持某些語言,但其實他們提供只是一個查詢的API,用戶要自己去調(diào)用 API 來取數(shù)據(jù)去實現(xiàn)一些算法。
那么所有這些帶給用戶的是什么?一個是選擇成本,另外一個就是遷移成本,從研發(fā)的角度來看,各式各樣的語言學習成本也非常高,所以造成了圖數(shù)據(jù)庫的普及非常難。

比較幸運的是,幾年前,業(yè)界或者說國際標準化組織也看到了這樣一個問題,所以大概在差不多 3-4 年前,就在我剛剛說的圖數(shù)據(jù)庫高速發(fā)展這幾年,包括 Oracle、Neo4j 在內(nèi)的一些公司,就組成了這樣一個 workgroup,這個組織是在標準化組織ISO-IECJTC1-SC32-WG3 下面的,目的就是希望推出一個圖數(shù)據(jù)庫查詢語言(Graph-Query-Language,簡稱 GQL)的標準。
當然整個標準的制定和推進是一個相當漫長的過程,那么到現(xiàn)在的話,基本上這個標準已經(jīng)接近最終的版本了。具體內(nèi)容這里就不展開說了,大概就是一個比較完善的查詢語言,包括數(shù)據(jù)定義、數(shù)據(jù)查詢、數(shù)據(jù)操作等等,而最關鍵的是,它跟 SQL 是一個姊妹篇,就是說跟我們剛才介紹的 SQL 有非常好的結合。這個工作組把 GQL 里面的很重要的一部分 patttern matching,我們說的圖的路徑的模式匹配這樣一部分抽出來,把這部分作為 SQL的一個 extension,就是把它作為SQL的一個擴展包,并制定了一個新的標準,就是對 SQL 的拓展。我們很高興地看到,這個標準基本上已經(jīng)被 SQL 的工作組接受了,那么這個東西其實也是 GQL 的核心,從一開始 GQL 和 SQL 之間就是一個緊密結合的關系。
統(tǒng)一圖查詢語言 GQL 為什么這么重要?
可以看到 GQL 是整個數(shù)據(jù)領域的第二個查詢語言標準。數(shù)據(jù)庫大家都知道,經(jīng)過幾十年的發(fā)展,數(shù)據(jù)庫的種類已經(jīng)是非常多了,對吧?數(shù)據(jù)庫的種類少說十、二十種肯定是有的,大家比較熟悉的可能有比如像時序數(shù)據(jù)庫、文檔數(shù)據(jù)庫等等,但這些數(shù)據(jù)庫都沒有自己的語言,要么就用 SQL,要么有一些自己的、各式各樣的一些查詢語言,但都沒有這樣另外制定一個標準——只有圖數(shù)據(jù)庫,現(xiàn)在國際標準化組織認識到了它的重要性,所以要制定這樣一個圖查詢語言的標準。這個標準可能是在明年年底或者后年年初會正式對外發(fā)布,一旦發(fā)布之后,它對投資客戶就像前面 SQL 在 80 年代后期推出標準一樣,會對整個行業(yè)帶來一個巨大的推動作用。
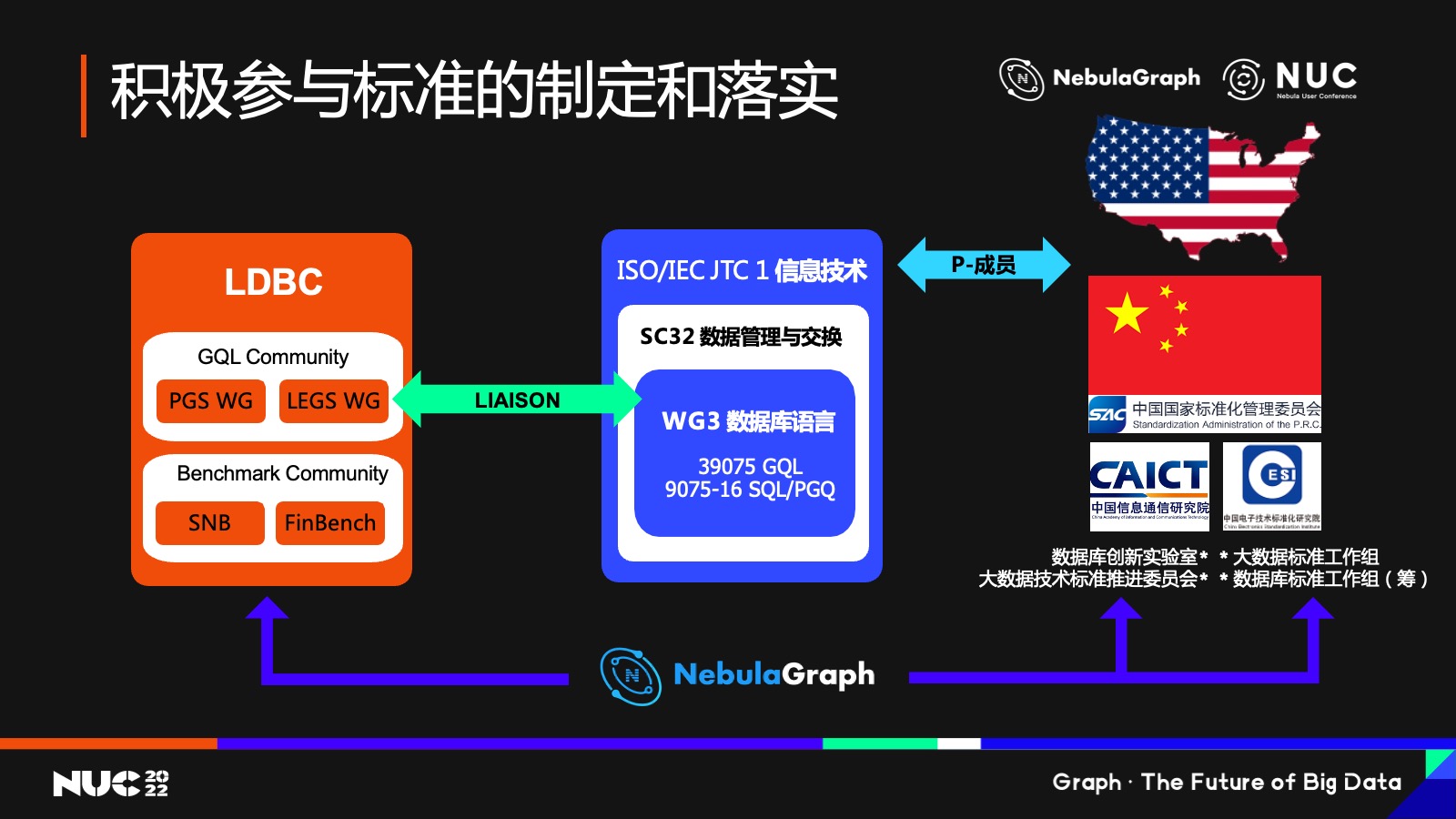
再講一下 NebulaGraph 在制定標準中的參與和推動作用。
我們作為圖數(shù)據(jù)庫公司,主要通過這樣的兩個不同的途徑——一是是通過國際化組織,大家都知道的 ISO,它的成員基本都是國家,并不是公司本身,我們在國內(nèi)主要就是通過 ISO 在國內(nèi)的代表電子四所,通過他們積極參與到 GQL 的制定當中,是目前的一條路徑。
第二條路徑的話是通過另外一個組織叫 LDBC,這個大家可能會比較熟悉。LDBC 是12 年左右由 Facebook 的一個實習生做出來的。當時 Facebook 做關系圖譜,社交圖譜怎么查詢、怎么來判斷圖數(shù)據(jù)庫或圖查詢效率?這位實習生就想來做一個 Benchmark,后來就變成了 LDBC。現(xiàn)在 LDBC 也是一個很重要的組織,它跟 GQL的工作組有非常緊密的結合聯(lián)系,而 NebulaGraph 現(xiàn)在也是LDBC的成員之一,也會通過我們在 LDBC 里面的影響力去影響這個標準。
2. 把握圖數(shù)據(jù)庫的主要應用場景
除了標準之外,我們再聊一聊圖數(shù)據(jù)庫未來的應用場景。
我認為圖數(shù)據(jù)庫更多的應用是在時效性。為什么這么說?大家可以看到目前圖數(shù)據(jù)庫主要的應用場景,從技術角度來區(qū)分,可以分成四類。第一類是實時關系探索,第二類是實時的異步計算,就是從實施的業(yè)務實時的 query 里面分出來的異步計算的這樣一個分支,它不會影響業(yè)務的實時性,但是有它在整個數(shù)據(jù)計算的時效性會比較高。第三個的話就是全圖分析,這個就是我們所理解的 AP,就是事后分析。第四個是圖算法,這也是圖和其他大數(shù)據(jù)不一樣一個地方,因為圖上面有很多算法,比如說社群發(fā)現(xiàn)、最短路徑等等這樣一些算法,那么這個算法也是基于全圖計算的。
在這四類應用里我們可以看到,前兩類比較偏 TP,也就是說我們說的 online service 或者說在線服務;后兩類偏 AP 一些,也就是事后分析。
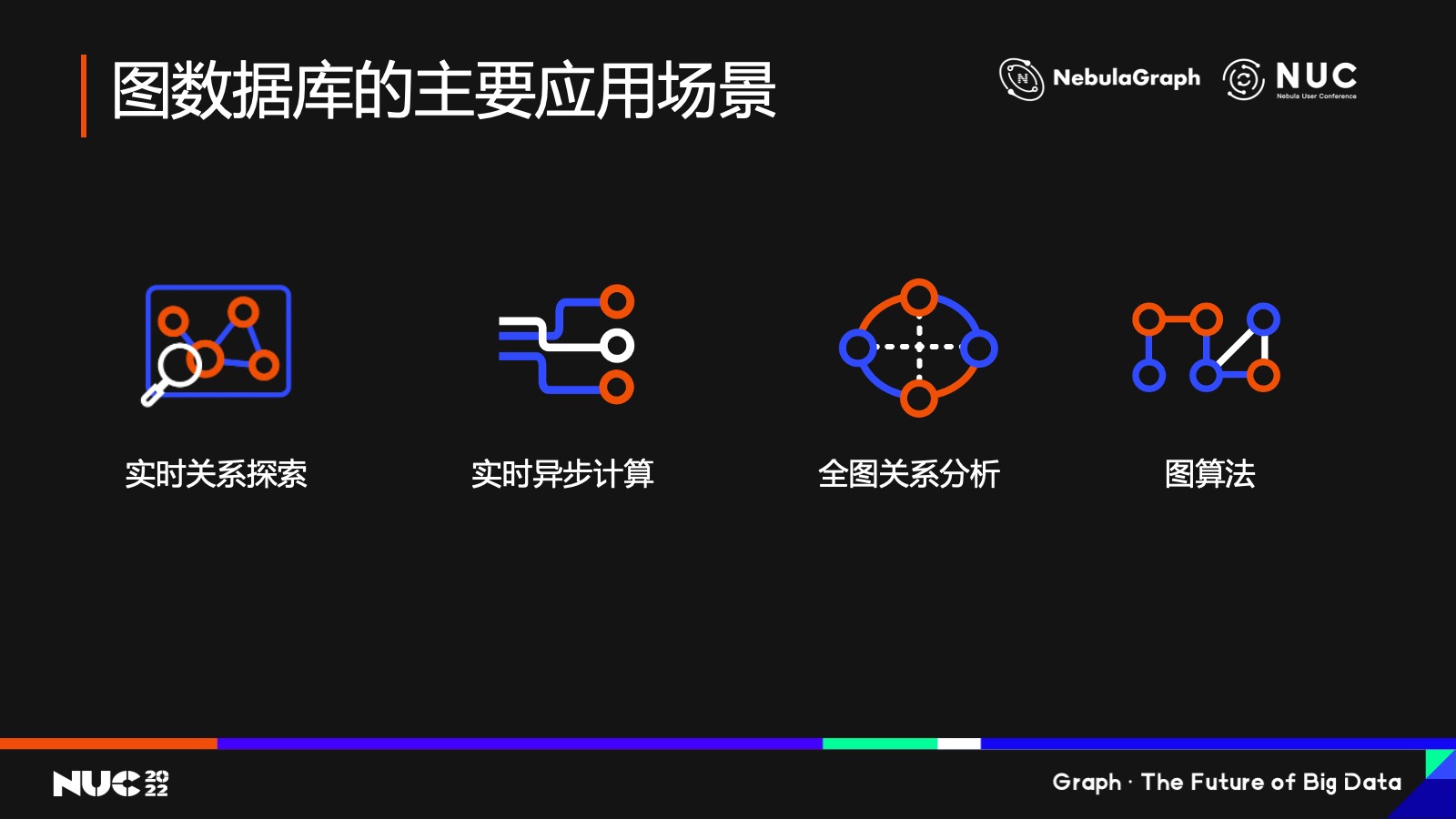
我認為相對于 TP,事后分析的場景更多是解決用戶的癢點,而不是痛點。
為什么這么說呢?首先在事后計算時,圖計算框架不是不可替代的。大家知道圖的計算框架有很多,最早的從谷歌的 Pregel 到后來的比如 GraphX,還有很多這樣一些離線的圖計算框架,它可以做圖分析的一些算法,但這個東西并不是不可替代的,我們用傳統(tǒng)的大數(shù)據(jù)系統(tǒng)也可以做同樣的事情。
比如說阿里,原來阿里比較有名的一個,基于 MapReduce 的一個大數(shù)據(jù)計算框架叫ODPS ,在 ODPS 上他們也做了一個圖的計算框架對吧?但是它是基于 ODPS 這個 MapReduce 算法來做的,所以說可以看到包括 Graphx,本身其實也不是一個純粹的圖計算的框架,它也是基于下面的基于流式計算 Spark 來做的對吧?
所以可以看到,圖計算框架本身所做的所有事情,用傳統(tǒng)大數(shù)據(jù)計算框架也都能做,唯一不同的地方是什么?可能不同的地方在于用傳統(tǒng)大數(shù)據(jù)框架來做的話,效率會慢一點。如在右邊那張圖顯示的,用圖的計算框架做的話只要 3 個小時,用傳統(tǒng)大數(shù)據(jù)框架來做,可能要 5、6個小時,那么對用戶來說,3 小時和 6 個小時的差別有嗎?肯定是有,但其實沒有那么大。

那么回到剛剛說的 AP ,我們認為,圖數(shù)據(jù)庫的實時計算能力可以解決在線業(yè)務的痛點問題。大家知道如果是在線的業(yè)務中,查詢速度如果比較慢的話,它對業(yè)務就會產(chǎn)生影響。
舉個例子,比如說金融行業(yè)的風控,銀行轉賬的風控場景,之前我們的風控都是做事后分析,現(xiàn)在絕大多數(shù)的銀行或者金融行業(yè)用的基于圖的分析,是不是有欺詐或洗錢行為基本都是離線分析,所謂離線就是 T+1 去分析今天好像有兩筆交易是有欺詐行為的或者有洗錢風險的,這樣做的問題是,當你分析出來有風險的時候,其實這個錢已經(jīng)出去了,轉賬已經(jīng)發(fā)生了,對吧?資損已經(jīng)發(fā)生了。
所以說從業(yè)務角度來說,他更希望什么?他更希望看到的是在事中,也就是說當這筆交易發(fā)生的時候,就能夠進行判斷,如果這筆交易有風險,我就要進行攔截,因為這樣對業(yè)務的好處就是我能直接減少損失。那么要把它做到能實時的、直接攔截的話,對整個的風控數(shù)據(jù)查詢的性能要求就非常高。
因為大家知道,比如說整個的交易鏈路,如果我們希望用戶轉一筆錢的時候,他的體驗比較好的話,就需要在比較短的時間,比如說半秒鐘或者更短的時間內(nèi)完成這筆交易。當然,整個鏈路當中要做很多事情,其中可能有一部分是做風控,給了風控比如 100 毫秒,風控系統(tǒng)必須在 100 毫秒內(nèi)給我一個結果,說有風險還是沒風險。當風控評估超時的時候,系統(tǒng)基本上都是認為這個東西是沒有風險,就直接過了。這時問題就來了,如果說你超時或者 100 毫秒內(nèi)做不了判斷的話,對整個的業(yè)務帶來的風險就越高。那么這樣也就是說在圖數(shù)據(jù)庫里,如果你要去做一些一跳兩跳三跳這種查詢的時候,你的延時就必須只能在規(guī)定時間內(nèi)完成,完不成就直接影響到風控動作的完成。
所以,能不能很快地完成查詢,其實就是解決了業(yè)務的一個痛點問題。當我們效率足夠高的時候,就可以賦能業(yè)務去做更多的這樣一些事情。而當我們能力不強的時候,業(yè)務只能依賴于事后分析。
基于以上這兩個的判斷,我們也可以聊聊 NebulaGraph 未來兩年大致的發(fā)展。一方面我們會全面支持 ISO GQL,便于快速實現(xiàn)標準化的對接。另一方面 NebulaGraph 也會持續(xù)提升查詢性能和并發(fā)度。作為一個分布式系統(tǒng),我們還需要有更強的彈性能力,以便能夠支持更大的數(shù)據(jù)量。當然,我們也不會放棄 AP,因為離線分析跟在線分析一起組成了圖這塊的閉環(huán),所以我們也會去集成更強的計算框架以及圖學習框架,打造一站式的圖解決方案,敬請各位期待。
那么,以上就是我今天要跟大家分享的內(nèi)容,謝謝大家。
[免責聲明]
原文標題: 聊一聊圖數(shù)據(jù)庫應用的現(xiàn)狀和 NebulaGraph 未來發(fā)展|NUC 2022
本文由作者原創(chuàng)發(fā)布于36氪企服點評;未經(jīng)許可,禁止轉載。




















