干貨分享|基于實(shí)時(shí)圖技術(shù)的信用卡申請(qǐng)反欺詐應(yīng)用

本文整理自普適智能 CTO 劉元弘在《圖創(chuàng)價(jià)值·圖+AI在金融行業(yè)的應(yīng)用實(shí)踐》的現(xiàn)場(chǎng)分享,一起來(lái)看看圖數(shù)據(jù)庫(kù)在信用卡反欺詐場(chǎng)景的應(yīng)用與優(yōu)勢(shì)。
常見(jiàn)的信用卡欺詐風(fēng)險(xiǎn)主要包括欺詐申請(qǐng)、偽卡盜刷、套現(xiàn)等。其中,信用卡申請(qǐng)欺詐通常指犯罪分子使用不正當(dāng)手段進(jìn)行信用卡申請(qǐng)、為獲得信用額度偽造申請(qǐng)信息、冒用他人信息申請(qǐng)信用卡,或申請(qǐng)人信息真實(shí)但惡意騙取信用額度不還。
在信用卡業(yè)務(wù)實(shí)踐發(fā)展過(guò)程中,欺詐申請(qǐng)的金額損失往往在欺詐損失案件中占據(jù)了非常大的比例,因此欺詐申請(qǐng)識(shí)別,是所有信用卡發(fā)卡機(jī)構(gòu)風(fēng)險(xiǎn)管理的一個(gè)重要組成部分。

隨著近些年金融線上化和渠道化的發(fā)展,信用卡申請(qǐng)欺詐逐漸呈現(xiàn)出兩大發(fā)展趨勢(shì):
一個(gè)是犯罪分子集團(tuán)化,越來(lái)越多欺詐是有組織的犯罪團(tuán)伙行為,團(tuán)伙案件對(duì)銀行造成的金額損失大、而且盜用信息還對(duì)銀行聲譽(yù)造成較大范圍影響;另一個(gè)是欺詐手段專業(yè)化,犯罪團(tuán)伙的欺詐手段越來(lái)越專業(yè)化,為了保證申請(qǐng)?zhí)峤宦屎蜕暾?qǐng)通過(guò)率,在批量申請(qǐng)時(shí),對(duì)申請(qǐng)信息、申請(qǐng)?jiān)O(shè)備等進(jìn)行專業(yè)包裝,加大了銀行反欺詐的難度。
在新發(fā)卡貸前審批反欺詐策略中,常見(jiàn)的做法是查詢申請(qǐng)人的人行征信、工商信息、學(xué)歷信息等,在自動(dòng)化審批環(huán)節(jié)對(duì)一部分還款能力和還款意愿較好或較差的申請(qǐng)人進(jìn)行通過(guò)或拒絕,剩下的部分流轉(zhuǎn)至人工審批。常見(jiàn)的流程如下:

在這個(gè)過(guò)程中,金融機(jī)構(gòu)往往需要處理大量的申請(qǐng)信息和用戶數(shù)據(jù),同時(shí)還涉及到人工審核效率及準(zhǔn)確度的問(wèn)題,因此需要我們搭建一套更智能且具有實(shí)時(shí)性的智能反欺詐系統(tǒng)來(lái)幫助金融機(jī)構(gòu)實(shí)現(xiàn)更高效、更精確的新發(fā)卡貸前審批。
為什么用圖技術(shù)進(jìn)行新發(fā)卡反欺詐
基于業(yè)務(wù)背景的介紹,傳統(tǒng)的信用卡審批流程中所使用的數(shù)據(jù)主要是統(tǒng)計(jì)學(xué)原理的規(guī)則或者模型,更多的是針對(duì)獨(dú)立個(gè)體的分析挖掘,但是當(dāng)個(gè)體的特征稀疏時(shí),則難以對(duì)個(gè)體做出全面有效的判斷。
特別是現(xiàn)在隨著欺詐手段呈現(xiàn)多樣化、專業(yè)化、團(tuán)體化等特征,傳統(tǒng)的專家規(guī)則和機(jī)器學(xué)習(xí)模型對(duì)通過(guò)多層關(guān)系進(jìn)行掩飾的復(fù)雜欺詐手段或者團(tuán)伙欺詐難以識(shí)別。
另外,由于目前發(fā)卡、運(yùn)營(yíng)、催收等各個(gè)環(huán)節(jié)的數(shù)據(jù)之間缺少必要的邏輯視圖和交叉校驗(yàn),容易導(dǎo)致金融機(jī)構(gòu)信息割裂,沒(méi)有統(tǒng)一的框架和視圖描述客戶的信用卡業(yè)務(wù)全生命周期,使得風(fēng)控決策/人工審核時(shí)缺少必要的數(shù)據(jù)支撐。
而圖技術(shù)具有將實(shí)體間的復(fù)雜關(guān)系直觀展示并納入模型學(xué)習(xí)的特性,能夠?yàn)樾庞每I(yè)務(wù)真實(shí)性審核提供更多維度的分析技術(shù)手段,恰好能彌補(bǔ)剛剛提到的傳統(tǒng)反欺詐手段的這些短板。

圖在新發(fā)卡反欺詐場(chǎng)景中的應(yīng)用流程
首先是用戶發(fā)起進(jìn)件流程,用戶申請(qǐng)進(jìn)件后信息會(huì)進(jìn)入到進(jìn)件中心,進(jìn)入進(jìn)件中心的同時(shí),系統(tǒng)會(huì)做兩個(gè)事情,一個(gè)是走實(shí)時(shí)流,另一個(gè)是離線流。
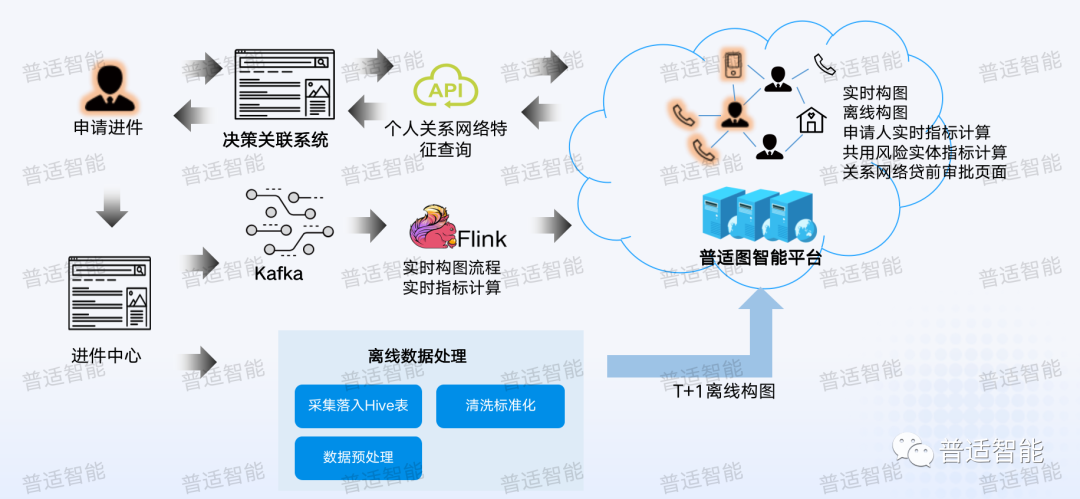
- 實(shí)時(shí)流
如果按照傳統(tǒng)走批的數(shù)據(jù)處理方式,可能第二天才會(huì)發(fā)現(xiàn)一些欺詐或作弊行為。像我們之前碰到有個(gè)團(tuán)伙10分鐘之內(nèi)提交了100多張新發(fā)卡申請(qǐng),通過(guò)實(shí)時(shí)流是有可能在他們申請(qǐng)前幾張的時(shí)候就把它攔截下來(lái),這就是實(shí)時(shí)的必要性。
走實(shí)時(shí)流,我們會(huì)讓進(jìn)件中心把數(shù)據(jù)寫(xiě)入到 kafka 里,然后通過(guò)一套實(shí)時(shí)引擎去監(jiān)聽(tīng)kafka,一旦監(jiān)聽(tīng)到有用戶提交進(jìn)件,接下來(lái)就用我們的圖平臺(tái)快速地配置各種各樣的規(guī)則和指標(biāo),快速地用圖引擎掃一遍所有的指標(biāo)來(lái)看看有沒(méi)有命中,并把結(jié)果寫(xiě)入到消息隊(duì)列中,然后提供給下游的一些決策系統(tǒng)進(jìn)行消費(fèi),同時(shí)會(huì)提供 API 給其他業(yè)務(wù)部門進(jìn)行調(diào)用,幫助業(yè)務(wù)人員進(jìn)行關(guān)聯(lián)決策。
- 離線流
除了走實(shí)時(shí)通道,我們也使用離線數(shù)據(jù)處理通道,就是下面的流程會(huì)進(jìn)入到底層數(shù)倉(cāng),然后走Hive去進(jìn)行T+1的離線構(gòu)圖,主要是防止實(shí)時(shí)流程中存在數(shù)據(jù)沖突,我們可以通過(guò)離線進(jìn)行校驗(yàn),之后再去進(jìn)行整體更新。
所以我們實(shí)際在幫客戶做圖的時(shí)候,并不是靜態(tài)圖,或者每天更新一次的一個(gè)流程。我們一般會(huì)起多個(gè)流程,包括實(shí)時(shí)流,各種全量的離線流,去保證我們圖庫(kù)數(shù)據(jù)處理的及時(shí)性和有效性。
如何構(gòu)建新發(fā)卡欺詐的圖譜
首先是本體模型,里面分為「點(diǎn)」代表的實(shí)體類型和「邊」代表的關(guān)系類型。實(shí)體類型包含個(gè)人、信用卡申請(qǐng)進(jìn)件、公司、地址、聯(lián)系電話、設(shè)備號(hào)、地址、網(wǎng)格化坐標(biāo)、車牌、營(yíng)銷員、代理人等實(shí)體;關(guān)系類型則主要包含父母、子女、擔(dān)保人、家庭住址等關(guān)系的本體模型。
我們構(gòu)建圖譜的數(shù)據(jù)來(lái)源主要是多個(gè)業(yè)務(wù)線的客戶數(shù)據(jù),以及客戶標(biāo)簽數(shù)據(jù),另外包含一些外部數(shù)據(jù)。擁有豐富的數(shù)據(jù)源,一方面提高網(wǎng)絡(luò)的關(guān)聯(lián)程度,另一方面豐富實(shí)體的屬性,能夠?yàn)殛P(guān)系網(wǎng)絡(luò)特征挖掘提供良好的數(shù)據(jù)基礎(chǔ)。
利用圖技術(shù)的反欺詐應(yīng)用
我們常用的圖的反欺詐分析主要通過(guò)四大類型完成,包含圖規(guī)則校驗(yàn)、圖指標(biāo)分析、社群分析和圖機(jī)器學(xué)習(xí)。
一、圖規(guī)則校驗(yàn) 所謂“圖規(guī)則”本質(zhì)上是一段判定的邏輯,這段邏輯是基于本體模型構(gòu)建一個(gè)復(fù)雜圖的拓?fù)浣Y(jié)構(gòu)來(lái)進(jìn)行表示和使用。業(yè)務(wù)可以使用圖規(guī)則功能,快速實(shí)現(xiàn)復(fù)雜關(guān)聯(lián)欺詐邏輯的可視化開(kāi)發(fā),校驗(yàn)申請(qǐng)人提供的信息和數(shù)據(jù)庫(kù)中數(shù)據(jù)是否一致或不一致。
以下圖為例,我們看到圖1這個(gè)人和另外一個(gè)人是關(guān)聯(lián)的,它們同時(shí)關(guān)聯(lián)同一個(gè)電話和工作地址,所以我們就可以去構(gòu)建這種圖的規(guī)則,然后去做一些規(guī)則校驗(yàn)。比如圖1可能表示工作地址相同,電話是相同的,代表他填寫(xiě)的信息是有效的。
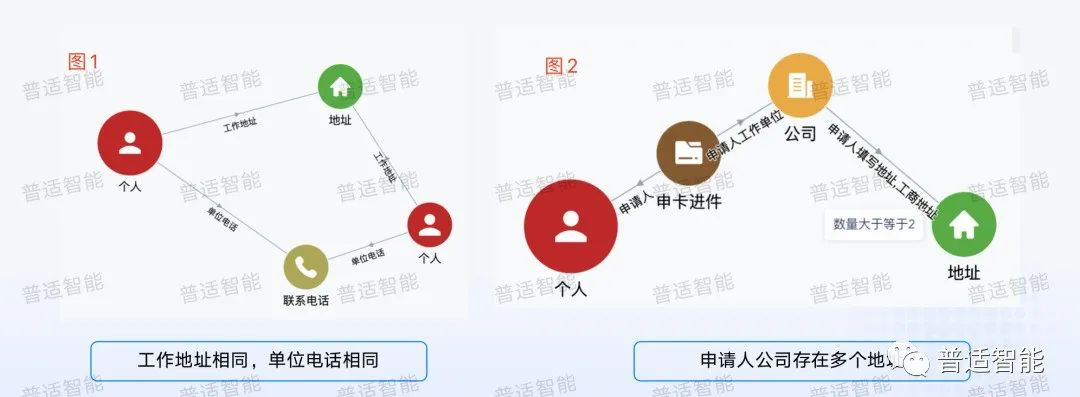
再看圖2,右邊紅色的點(diǎn)代表一個(gè)人,這個(gè)人申請(qǐng)了一張信用卡,他填寫(xiě)資料后又拉出了一個(gè)地址,地址的條件數(shù)量大于等于2,也就是這個(gè)人一張申請(qǐng)卡,卻存在兩個(gè)不同的地址,這對(duì)風(fēng)控來(lái)說(shuō)也是比較有效的指標(biāo)。
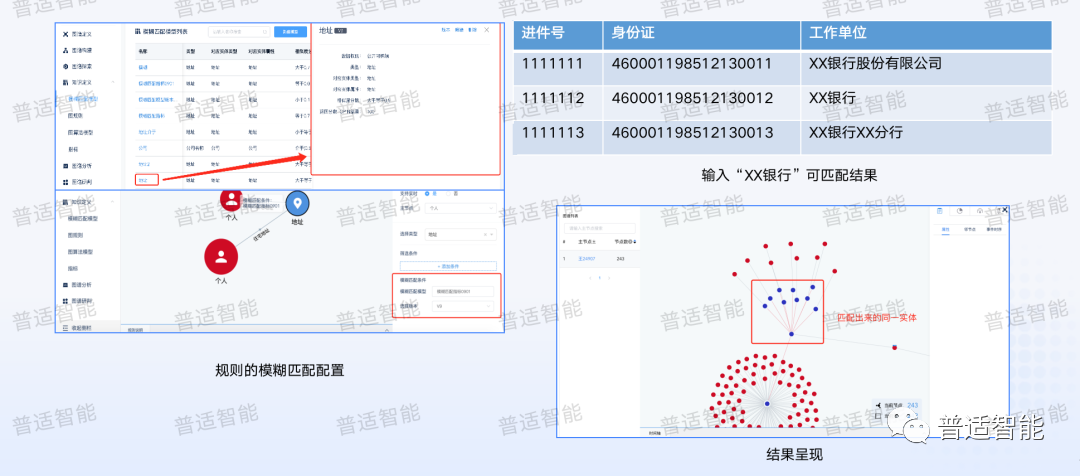
能把圖規(guī)則做好,尤其是在銀行,重點(diǎn)在于兩個(gè)數(shù)據(jù)維度,一個(gè)是企業(yè)的維度,另一個(gè)是地址的維度,但是金融用戶一般有個(gè)痛點(diǎn),就是每個(gè)人填寫(xiě)信息時(shí),每次填寫(xiě)的地址不一定是一樣的,以前很多引擎沒(méi)辦法準(zhǔn)確判斷這兩個(gè)地址是否是同一個(gè)。
為了強(qiáng)化反欺詐引擎的效果,在圖規(guī)則引擎之中引入了文本相似度算子,我們?cè)缙谧鲞^(guò)一些NLP的東西,所以我們把一些NLP尤其是關(guān)于地址對(duì)齊和企業(yè)名稱對(duì)齊的類型,構(gòu)建了自己的算法,把這個(gè)算法加入到了模型中,它就可以配置一些更有意思的東西,比如:我個(gè)人關(guān)聯(lián)的地址,關(guān)聯(lián)的同事A、同事B、同事C等等,我們的地址可以填的不一樣,有的填了路,有的沒(méi)有填路,有的填了區(qū),有的沒(méi)填區(qū),其實(shí)這個(gè)很常見(jiàn)的,那我們就可以把所有填寫(xiě)不同的地址聚合到一塊,去構(gòu)建一些高質(zhì)量的規(guī)則,幫助業(yè)務(wù)構(gòu)建更強(qiáng)大的欺詐校驗(yàn)?zāi)芰Α?/p>
地址和企業(yè)對(duì)齊準(zhǔn)確率經(jīng)過(guò)大型股份制銀行的業(yè)務(wù)校驗(yàn),準(zhǔn)確率在98%以上。
二、圖指標(biāo)分析
圖指標(biāo)其實(shí)和原本的指標(biāo)體系是完全一樣的,只是構(gòu)建這個(gè)指標(biāo)時(shí)會(huì)有幾個(gè)特殊點(diǎn),通過(guò)維度、標(biāo)簽、客群。邏輯就是先構(gòu)建一個(gè)有效的關(guān)聯(lián)性,常用的一些構(gòu)建關(guān)聯(lián)性的維度包括:同一單位、同一家庭、同一設(shè)備、同一LBS、同一聯(lián)系方式、同一推薦人、同一親屬等等,這就是我們說(shuō)的關(guān)系維度。

我們會(huì)在關(guān)系維度上增加一些標(biāo)簽,比如:用左邊和右邊關(guān)聯(lián)放到一塊,我們就可以構(gòu)建成一個(gè)有效的規(guī)則。
舉例:
「同一單位」(左)關(guān)聯(lián)出的人在「黑名單」(右)的一個(gè)數(shù)目
「同一家庭」(左)關(guān)聯(lián)出了「申請(qǐng)被拒絕」(右)的情況
「同一設(shè)備」(左)關(guān)聯(lián)出其他人「逾期」(右)的情況
我們就可以把這些信息全部組合起來(lái),結(jié)合我們自己的一個(gè)考慮,用維度關(guān)聯(lián)右邊這種常用的標(biāo)簽和指標(biāo),構(gòu)建一些有效的規(guī)則和邏輯,從而識(shí)別資料異常的申請(qǐng)人,或申請(qǐng)人關(guān)聯(lián)的特定客群。
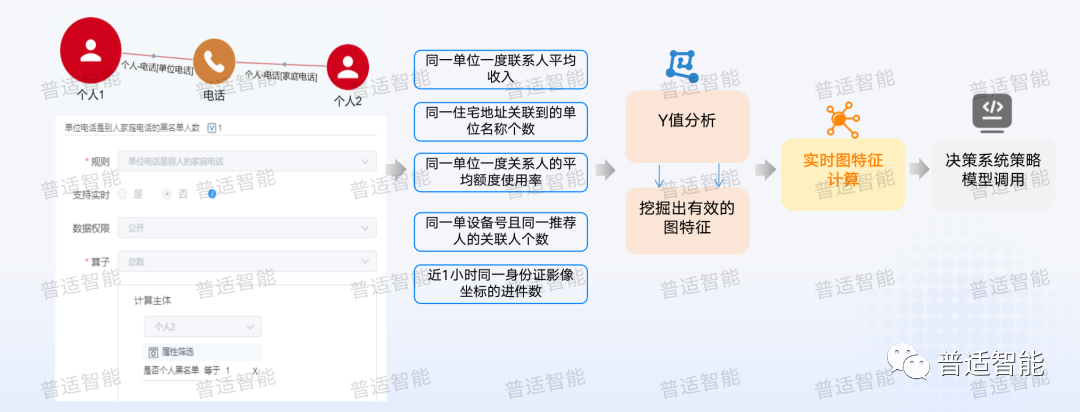
我們?cè)谟脠D的過(guò)程中,規(guī)則是全局的,需要有業(yè)務(wù)經(jīng)驗(yàn),所以這種方式還是有缺陷的。我們常用的規(guī)則是強(qiáng)關(guān)聯(lián)關(guān)系的維度,比如:「電話設(shè)備」,很難出現(xiàn)一個(gè)電話被很多人使用的情況。但在平時(shí)采集的數(shù)據(jù)是有很多的弱關(guān)聯(lián),也是很有效的維度,比如:「WiFi 設(shè)備」,幾個(gè)人同時(shí)接入到相同的 WiFi設(shè)備,并不能代表他們之間有強(qiáng)關(guān)系,但是起碼代表有弱關(guān)聯(lián)。可能在一個(gè)辦公樓,也可能住的是同一個(gè)地方。再比如說(shuō)「IP」也是很典型的弱關(guān)聯(lián),還有很多其他的弱關(guān)聯(lián),包括同一個(gè)單位,并不能夠代表你們就一定認(rèn)識(shí),尤其是對(duì)一些規(guī)模比較大的單位,這個(gè)時(shí)候我們就可以用圖算法,通過(guò)平臺(tái)可視化界面構(gòu)建規(guī)則和圖指標(biāo)。
三、社群分析(Louvain)
圖算法的核心主要是幫助我們整合一些弱關(guān)聯(lián),尤其是有像Louvain 這種,在我們緊密相連的大圖中,就可以拿 Louvain 去切一些客戶圈和客戶之間的社群,比如:有10個(gè)人,不可能10個(gè)人都是單線相連的,A認(rèn)識(shí)B,B認(rèn)識(shí)C,C認(rèn)識(shí)D,Louvain 切出的結(jié)果基本上就是A認(rèn)識(shí)B,B認(rèn)識(shí)C,然后A也認(rèn)識(shí)C,這才是Louvain里面跑出來(lái)的結(jié)果,就可以通過(guò)這個(gè)算法,再加上邊的權(quán)重,比如:家庭親屬的關(guān)聯(lián)性設(shè)成1,同一IP設(shè)置成0.1,再去進(jìn)行社群的切分,就可以得到業(yè)務(wù)想要的社區(qū)結(jié)果。

既然我們用了社區(qū)切分算法去得到一個(gè)好的社區(qū),社區(qū)里面的人必然是緊密關(guān)聯(lián)的,就可以用社區(qū)做一些有意思的指標(biāo),比如:整個(gè)社區(qū)進(jìn)入黑名單的概率是多少,就是所謂的黑名單的濃度,逾期的濃度,業(yè)務(wù)通過(guò)計(jì)算不同維度下的客群指標(biāo),就可以挖掘可疑的個(gè)體。
四、圖機(jī)器學(xué)習(xí)
首先圖可以幫助我們機(jī)器學(xué)習(xí)去更快速構(gòu)建特征。在沒(méi)有做機(jī)器學(xué)習(xí)之前,傳統(tǒng)的做法是需要人力把很多特征整合成一張寬表,再傳入到建模平臺(tái)。但是圖從本質(zhì)上來(lái)說(shuō),就是連接了一張又一張的表,這種表的關(guān)聯(lián)性完全可以通過(guò)圖進(jìn)行整合,再去拉取特征(Feature)的時(shí)候就可以用前面說(shuō)的圖指標(biāo),放到機(jī)器學(xué)習(xí)里面指標(biāo)就是一個(gè)特征(比如:指標(biāo)是某個(gè)人的逾期率為0.6,那0.6是一個(gè)數(shù)值,但它放到對(duì)應(yīng)的機(jī)器學(xué)習(xí)就是一個(gè)特征),拉取的指標(biāo)就可以作為其中一個(gè)特征濃度進(jìn)行訓(xùn)練。
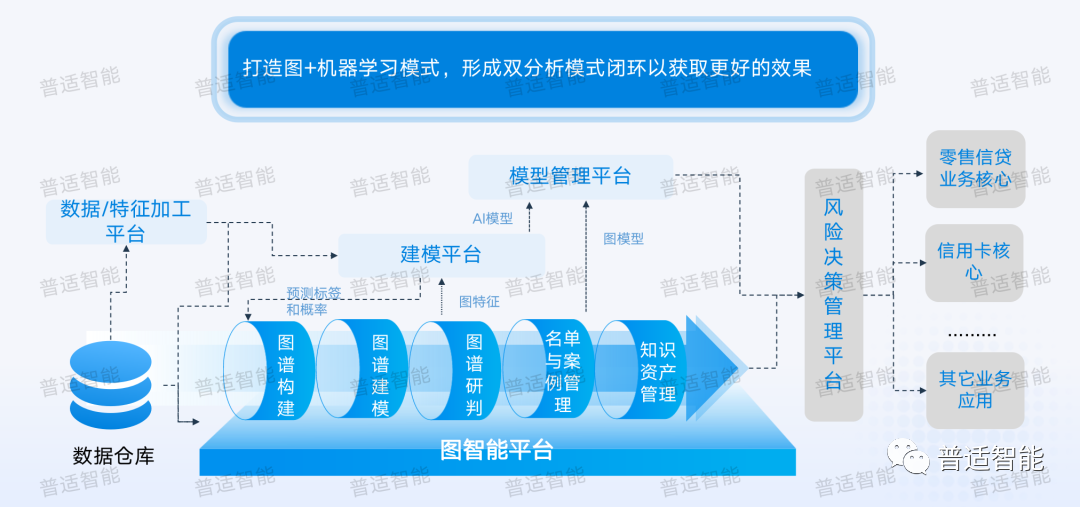
對(duì)于我們客戶行為來(lái)說(shuō),或者客戶特征特別稀疏的時(shí)候。很多企業(yè)都會(huì)維護(hù)潛在客戶名單,既然是潛在客戶,就可能存在不知道他的姓名,或者說(shuō)只知道他碎片化的信息,可能他只是點(diǎn)了一個(gè)廣告或者一個(gè)鏈接,但實(shí)際上我們獲取到了他的IP,就可以通過(guò)圖機(jī)器學(xué)習(xí)平臺(tái),挖掘有效的特征,在決策系統(tǒng)上部署策略,運(yùn)用于新發(fā)卡實(shí)時(shí)審批環(huán)節(jié)。 另外我們還在做一些有意思的事情,我們把機(jī)器學(xué)習(xí)的一些結(jié)果放回圖里去看。就拿預(yù)測(cè)VIP來(lái)說(shuō),模型得出大于0.5,你會(huì)認(rèn)為它是VIP,小于0.5你認(rèn)為它不是 VIP,如果我們?cè)俣然貓D里,我們給是否是VIP這樣的概率,增加一個(gè)屬性,預(yù)測(cè)結(jié)果放回圖里看,就可以識(shí)別高概率的VIP客群,高可能的關(guān)聯(lián)圈,這也就是下期我們要分享的【潛在VIP挖掘】的場(chǎng)景應(yīng)用。
普適的圖智能平臺(tái)在某股份制銀行上線后取得了不錯(cuò)的成效。使用圖技術(shù),進(jìn)行實(shí)時(shí)構(gòu)網(wǎng)和實(shí)時(shí)圖指標(biāo)計(jì)算,優(yōu)化決策系統(tǒng)。風(fēng)控效果提升近3倍,預(yù)計(jì)每年挽損1000萬(wàn)以上。
[免責(zé)聲明]
原文標(biāo)題: 干貨分享|基于實(shí)時(shí)圖技術(shù)的信用卡申請(qǐng)反欺詐應(yīng)用
本文由作者原創(chuàng)發(fā)布于36氪企服點(diǎn)評(píng);未經(jīng)許可,禁止轉(zhuǎn)載。




















