指針走到了九點,凝視著時鐘的技術招聘官Jasmine從昏沉中回到現實,她將咖啡連同嘆息一口抿了下去,并端正坐在電腦前。又是一天的評卷日……
技術招聘已持續數周,公司篩選出了100位嵌入式工程師候選人的技術測評答卷,每份評卷需要30-45分鐘,100份便是妥妥50個小時,想起來就頭大。
審完十多份試卷后,她疲勞得實在需要休息一下,但恍惚間一個不安的念頭閃過她腦海……自己前后的打分是否一致呢?缺乏客觀標準,讓她的打分異常艱難。
“如果AI能幫我評卷,那就好了......”
Jasmine兩眼無神,回望向時鐘.....
既然如此痛苦,為何Jasmine的公司還要采用問答題進行技術測評呢?
比起常見的選擇題、編程題,問答題更多需要候選人書寫答案。除了考察候選人的具體知識點外,能從其解題思路與觀點中,更加深入了解他的設計思路、解決方案,和對概念的理解;從答案的邏輯性、組織性和完整性等方面,企業可以獲得更多信息,了解候選人的深入思考、邏輯與創造性思維。
但這類問題卻給技術招聘官的評卷帶來了巨大的困難,原因有如下兩點:
1. 耗費海量時間與精力
國外一份研究顯示,在技術測評中,考慮到不同題型與難度,招聘官平均須花費30-45分鐘來評審問答題,而面向高階技術工程師的問答題評審,甚至會高達60分鐘。
一份對谷歌技術面試官的采訪也表示,他們往往每周都會花費數十小時以上的時間來評估問答題試卷,以決定候選人進入下一輪面試的資格。
從中可知,人工評估技術問答題,的確需要耗費海量時間。
2. 評審主觀性強,招聘官間缺乏一致共識
問答題由于沒有明確的正確or錯誤答案,導致每位招聘官對回答內容都有自己的理解。候選人是否具備某項能力,強烈依賴于該招聘官的個人觀點;并且一個團隊內招聘官A/B/C,針對一個候選人的一個答案,還會產生三種不同的觀點,導致“一千個哈姆雷特“的問題,彼此很難有一致性。
曾發表于《國際選拔與評估》雜志的一項實驗就顯示:實驗者讓3名評審人以5分制,對兩位候選人的答卷進行評分,結果候選人A的評分為5 、4、 2,候選人B的評分為 2 、3、 5,一個人的答卷,在不同人眼里存在著巨大差值,可見評審極易受個人主觀因素的影響。
正如招聘官Jasmine所想 ,如果能將AI引入復雜的問答題中,將答案內容數據結構化,并依據算法建立準確明晰的評估標準,不僅能實現評分的一致性,還能通過自動化流程,節省海量的工作時間。
隨著人工智能高速發展,AI早已融入日常工作之中。ShowMeBug深知AI的巨大意義,采用最新AI大模型,實現獨有的問答題AI評分,打造全自動化、高可靠性的評分體系,評卷更加客觀化、自動化,評卷時間0投入!
ShowMeBug自動AI評判功能的核心思路,在于設定了評分維度,并輔以AI自動化功能。通過更高效的自動化方式,節省海量評卷時間;并通過明確的評分標準,更客觀地評價候選人的答案,保障高度一致性、可靠性、客觀性的評分結果。
具體來說,AI評分的高一致性使得同樣答案的每次評分都相同,屏蔽了主觀因素干擾;可靠性保證了評分是根據設定的維度所作出,讓評分有標準可依;客觀性使得評分結果僅圍繞著維度的內容展開,不會考慮與內容無關的角度。
我們可舉一例來說明:
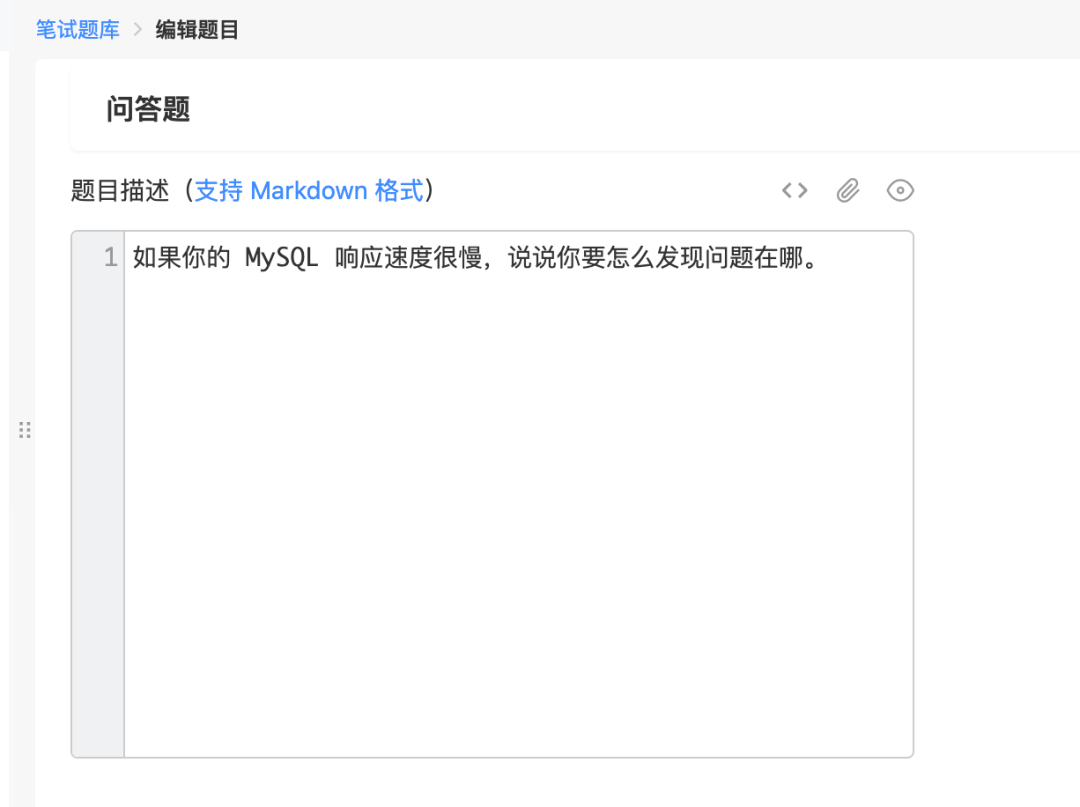
現在假設企業需要招聘 Java 后端開發工程師,那么技術面試官可以出題考察候選人SQL 優化的能力,這時候企業可以在 ShowMeBug 后臺設置一道題來考核候選人在My SQL性能問題上的排查思路:
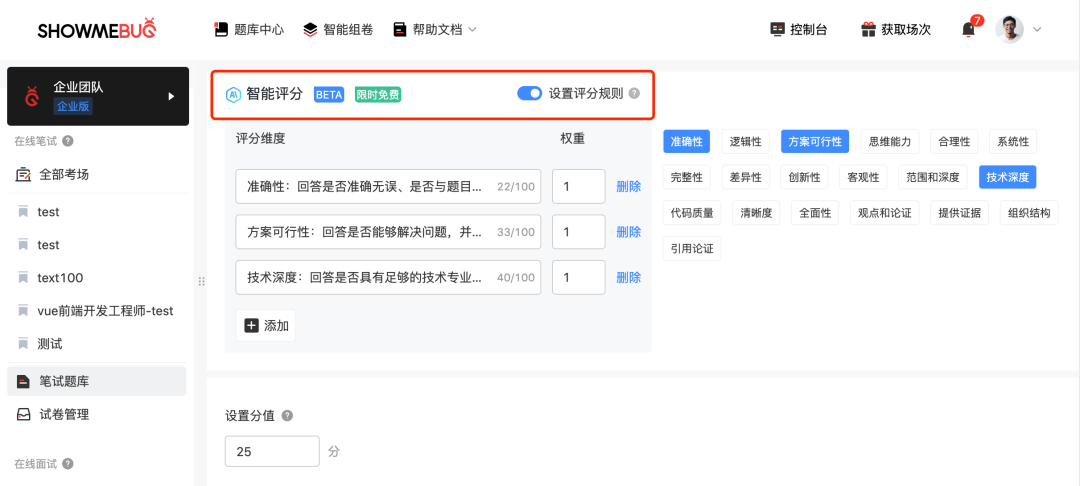
Jasmine作為這家企業的技術面試官,可在試題參數設置中,打開內置的AI智能評分功能。ShowMeBug 預設了19種常見的評分維度,包括答題的準確性、完整性、技術深度、邏輯思維等等。
同時,ShowMeBug 也支持企業根據自身需求自定義評分維度。設置多種評分維度的目的,是為了避免不同評卷官可能會因為判斷標準不同,而給出不同得分,導致評分結果帶有較大主觀性的情況。
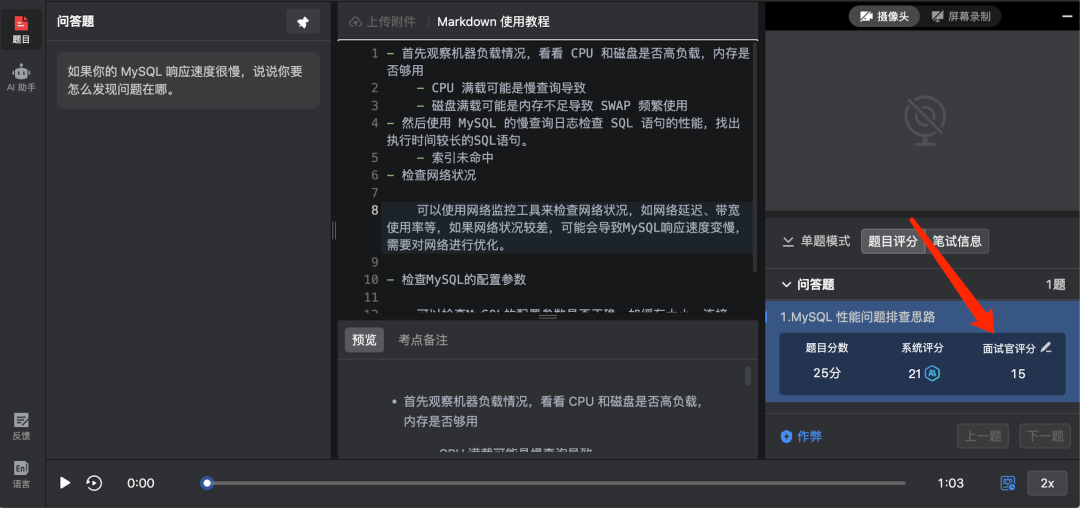
設置好試題、試卷和考場后,企業邀請候選人Shawn進行技術測評。候選人Shawn很快就在ShowMeBug 上提交完試卷。企業進入到了評卷環節。
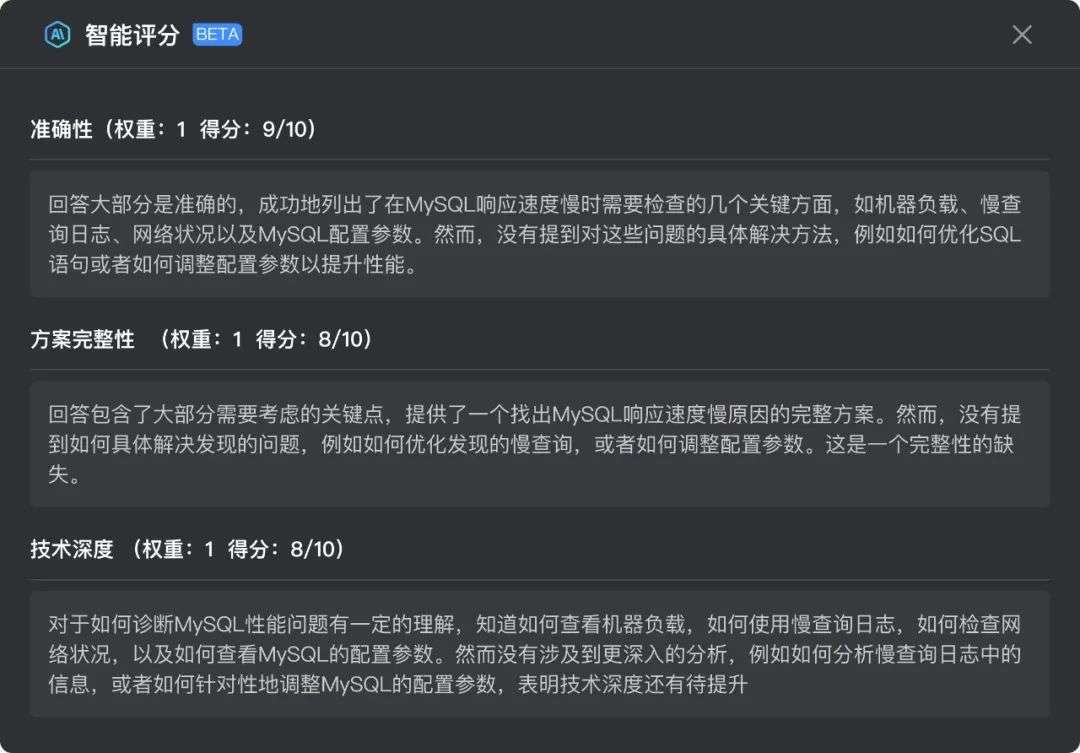
企業進入評卷界面,我們可以看到,AI已經根據剛剛我們設置的評分維度,對候選人的答案進行打分,并提供了每個評分維度的評分理由。
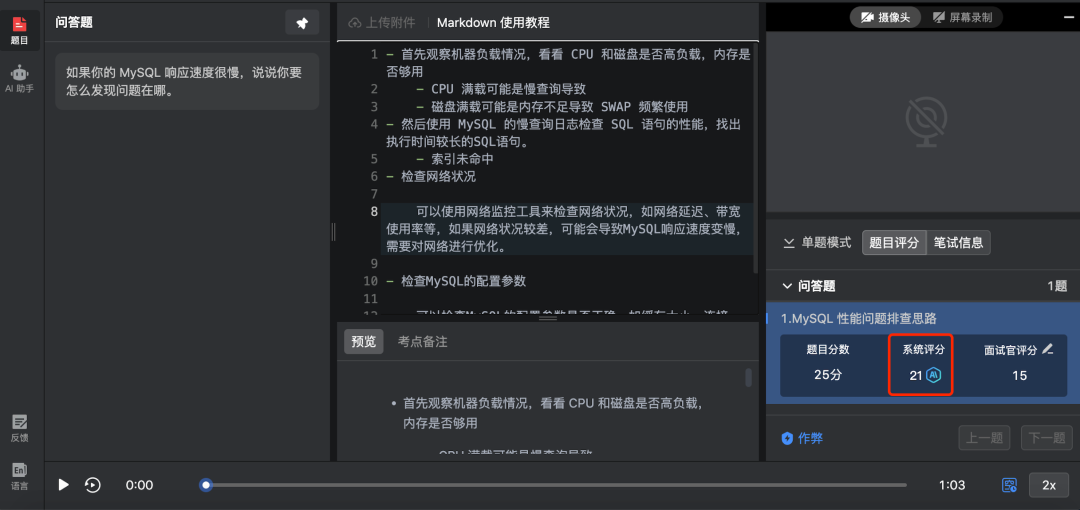
AI的運用,使得同一份答案多次測評,所得的分數完全一致,避免了招聘官面對同一份答案,在不同時間,或者不同招聘官之間,因個人主觀因素所導致的評分差異,保障了每次測評的一致性與客觀公正。
從上圖可知,候選人Shawn針對該題在各維度上,均能滿足基本要求,但在各維度上也有欠缺之處。當然,企業若針對該候選人,在這道題上的回答有自己的看法,也可在保持評分客觀性的同時,根據自己的專業判斷和經驗,進行適當的調整。
評卷后,招聘官可一鍵生成人才報告,將Shawn與其他候選人對比,也可發給其他招聘官一同評測,減少個人主觀判斷的因素。
通過ShowMeBug 問答題AI智能評分,企業便能以AI自動化方式,通過不同維度,測評海量候選人問答題的答案,幫助她節省大幅的評卷工作量;也能讓技術面試官和項目負責人之間擁有了一個客觀標準,規避彼此之間主觀分析產生的差異,對所評分數達成一致的共識;并最終深入幫技術面試官考察候選人實際工作與深入思考的能力。
看到這里,想必大家仍會對問答題AI評分功能產生疑慮:AI的結論靠譜么?穩定性怎么樣?
安心,ShowMeBug 針對AI評分的可靠性、一致性與客觀性,進行了完善的性能測試,測試結果為:問答題Al評分具有較高的一致性和客觀性,評分行為穩定,具有高的可靠性。
今天這篇就介紹到這兒了。等下,就這樣了?當然遠遠不夠,技術測評+AI已經被我們卷出新高度了~有關如何實現技術評卷時間0投入,我們還有one more thing……敬請期待下一篇吧~:)