中科大&京東最新成果:讓AI像真人一樣演講,手勢打得惟妙惟肖

豐色 發自 凹非寺
量子位 | 公眾號 QbitAI
人類在說話時會自然而然地產生肢體動作,以此來增強演講效果。

現在,來自中科大和京東的研究人員,給AI也配備了這樣的功能——
隨便丟給它一段任意類型的演講音頻,它就能比劃出相應的手勢:
配合得非常自然有沒有?
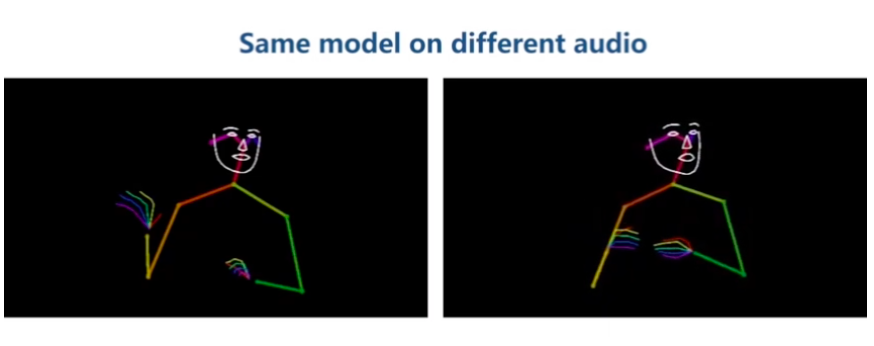
對于同一個音頻,它還能生成多種不一樣的姿勢:

由于每個人的習慣并不相同等原因,演講和肢體動作之間并沒有一套固定的對應關系,這也導致完成語音生成姿勢這一任務有點困難。

△ 極具代表性的意大利人講話手勢
大多數現有方法都是以某些風格為條件,以一種確定性的方式將語音映射為相應肢體動作,結果嘛,也就不是特別理想。
受語言學研究的啟發,本文作者將語音動作的分解為兩個互補的部分:姿勢模式(pose modes)和節奏動力(rhythmic dynamics),提出了一種新穎的“speech2gesture”模型——FreeMo。
FreeMo采用“雙流”架構,一個分支用于主要的姿勢生成,另一個分支用于“打節奏”,也就是給主要姿勢施加小幅度的節奏動作(rhythmic motion),讓最終姿勢更豐富和自然。
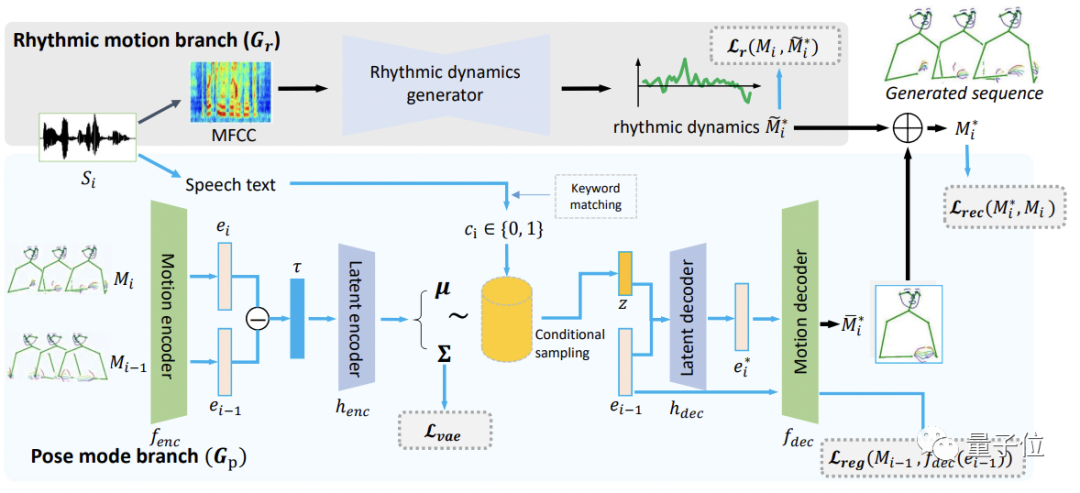
前面說過,演講者的姿勢主要是習慣性的,沒有常規語義,因此,作者也就沒有對姿勢生成的形式進行特別約束,而是引入條件采樣在潛空間學習各種姿勢。
為了便于處理,輸入的音頻會被分成很短的片段,并提取出語音特征參數MFCC和演講文本。
主要姿勢通過對演講文本進行關鍵字匹配生成。
語音特征參數MFCC則用于節奏動作的生成。
節奏動作生成器采用卷積網絡構成,具體過程如圖所示:
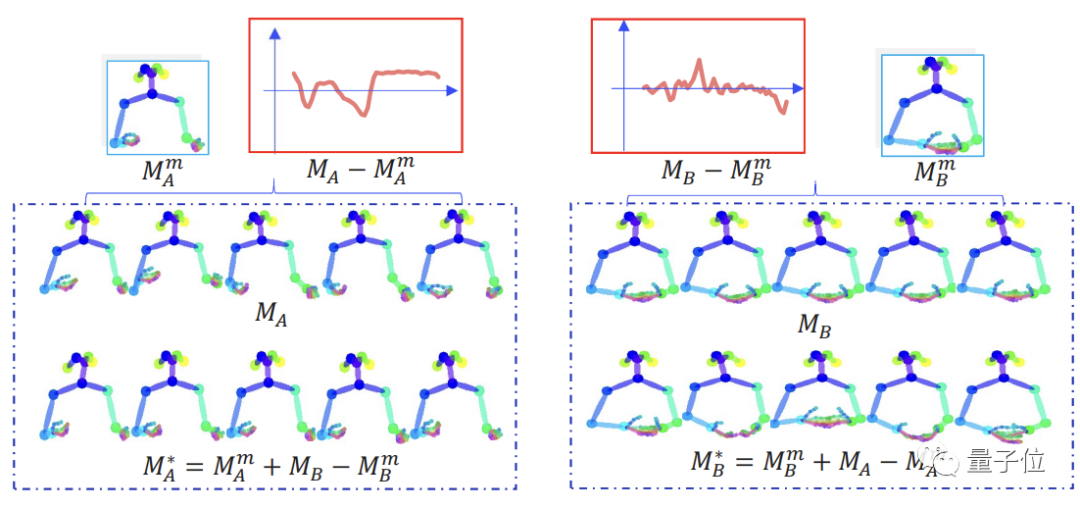
MA和MB是訓練集中隨機抽取的兩個動作序列。
紅色框表示動作序列平均姿勢的偏移量。通過交換倆個序列的偏移量,模型就可以在不影響主要姿勢的情況下進行“節奏”控制。
FreeMo的訓練和測試視頻包括專門的Speech2Gesture數據集,里面有很多電視臺主持人的節目。
不過這些視頻受環境干擾嚴重(比如觀眾的喝彩聲),以及主持人可能行動有限,因此作者還引入了一些TED演講視頻和Youtube視頻用作訓練和測試。

對比的SOTA模型包括:
-
采用RNN的Audio to Body Dynamics (Audio2Body)
-
采用卷積網絡的Speech2Gesture (S2G)
-
Speech Drives Template (Tmpt,配備了一組姿勢模板)
-
Mix StAGE(可以為每一個演講者生成一套風格)
-
Trimodal-Context (TriCon,同樣為RNN,輸入包括音頻、文本和speaker)
衡量指標一共有三個:
(1)語音和動作之間的同步性;
(2)動作的多樣性;
(3)與演講者的真實動作相比得出的質量水平。
結果是FreeMo在這三個指標上都超越5個SOTA模型獲得了最好的成績。
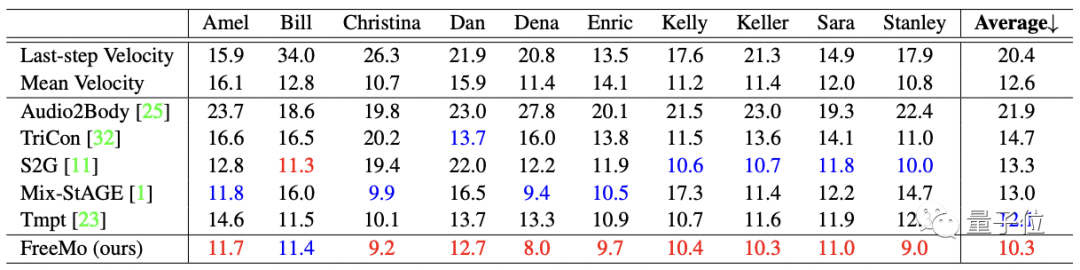
△ 同步性得分,越低越好
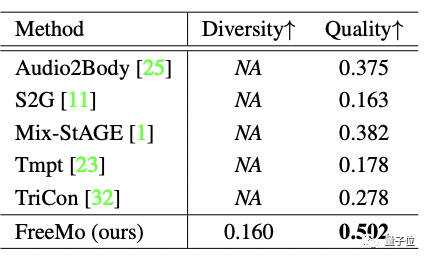
△ 多樣性和質量水平得分
ps. 由于5個SOTA模型在本質上都是學習的確定性映射,因此不具備多樣性。
一些更直觀的質量對比:
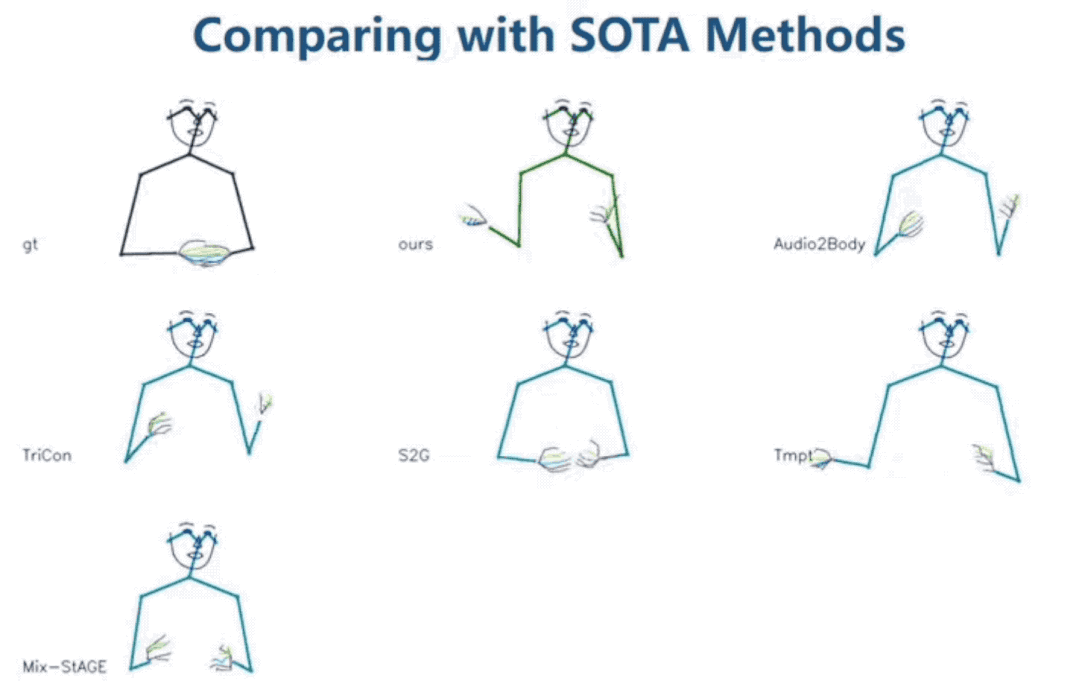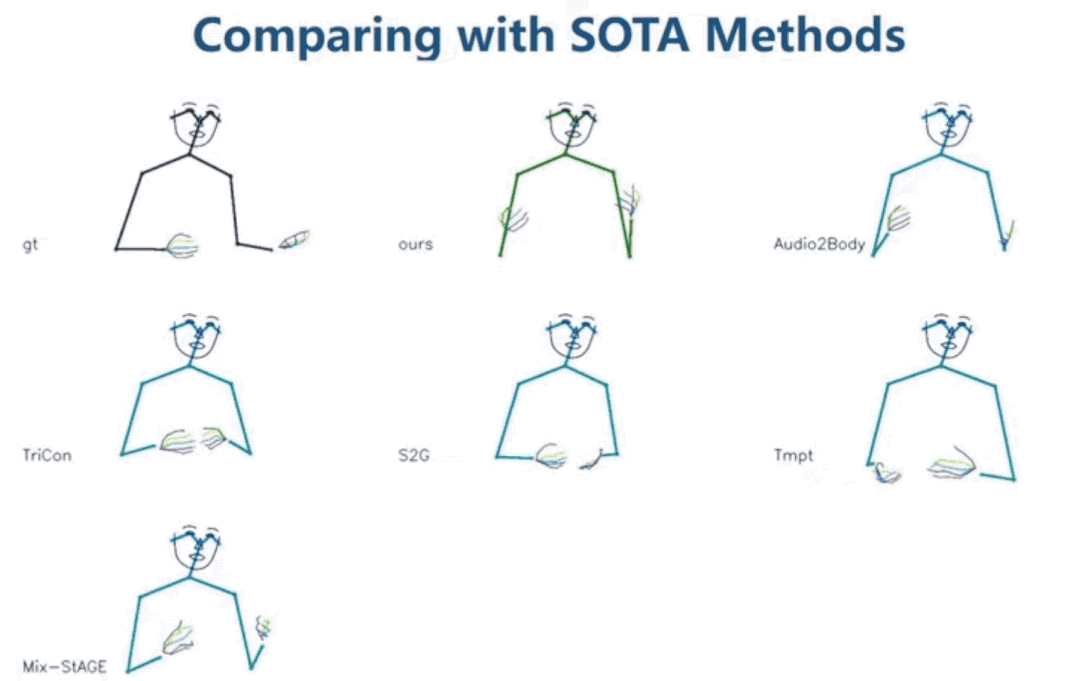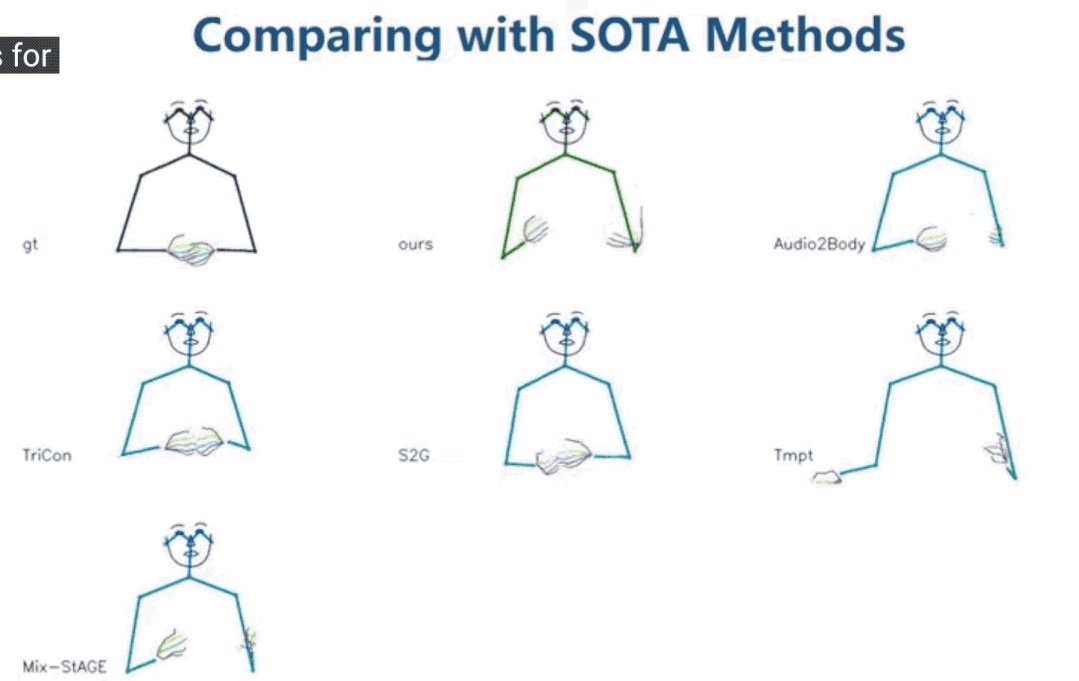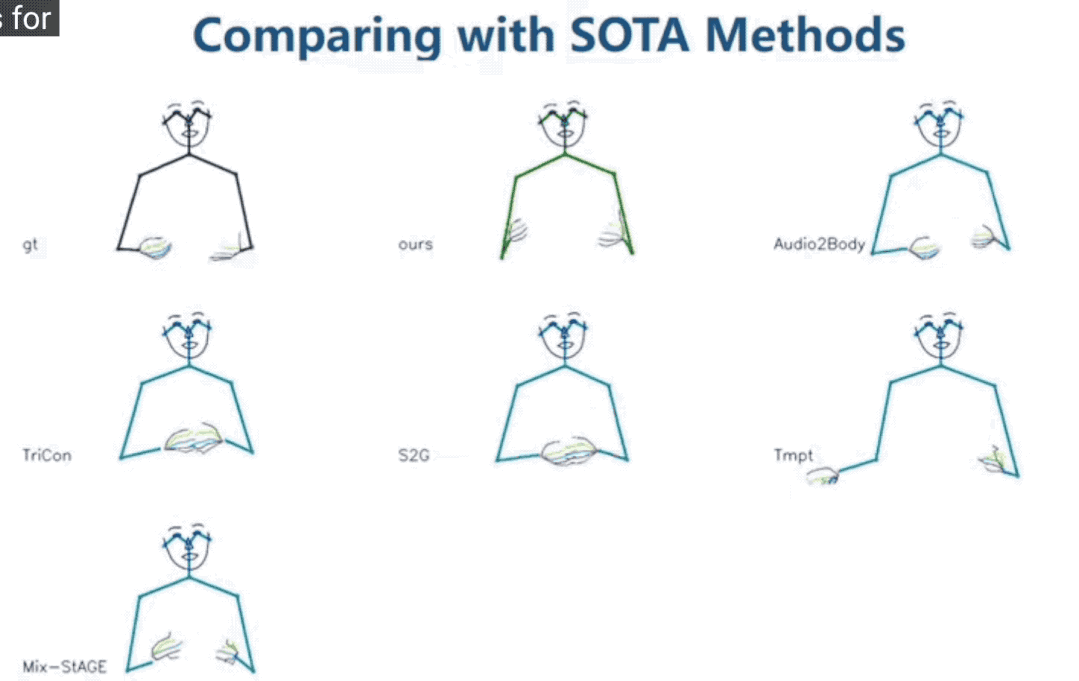
最左上角為真實演講者的動作,可以看到FreeMo的表現最好(Audio2Body也還不錯)。

一作為Xu Jing,來自中科大。
通訊作者為京東AI平臺與研究部AI研究院副院長,京東集團技術副總裁,IEEE Fellow梅濤。
剩余3位作者分別位來自京東AI的研究員Zhang Wei、白亞龍以及中科大的孫啟彬教授。
論文地址:
https://arxiv.org/abs/2203.02291
代碼已開源:
https://github.com/TheTempAccount/Co-Speech-Motion-Generation
本文來自微信公眾號 “量子位”(ID:QbitAI),36氪經授權發布。





















