gan的模型

一、質量提高方面—GAN的三種模型
(一)Wasserstein GAN(WGAN)
GAN的問題,曾在Wasserstein的一篇論文中得到充分表達,當真實樣本和生成樣本的交集不可度量時,就會出現問題。
其實真實樣本和生成樣本不能說絕對沒有交集,而是它們的交集要么是空集要么是不可度量,因為它是一個低微的流形。
舉例:在一個三維的立體空間中,有一個二維平面和另一個二維平面,它們的相交是一條直線,這條直線在三維空間中是沒有體積的。現在假設是10000維的高維空間,我們剛才講的圖片屬于低微流形,也就是10000維空間中一個低維的超平面而已。與隨機向量產生的生成樣本之間,是兩個超平面,就算有交集,交集的體積也是0(這個體積是多維體積,而不是真實體積)。
這會使得我們的運算出問題,回顧上面的公式:有真實樣本和生成樣本的分布,它們之間的交集體積為0,那么X和G(Z)幾乎沒有可度量的重合部分,這樣的數對真實樣本來說,它的分布為0,對生成樣本的分布來說,概率為0,兩個必有一個為0。我們知道對數里面取0,就會是一個負無窮,這個時候就會產生問題,使得訓練進行不下去。
這里,可以看成是log對真實樣本分布和生成樣本分布的求積分。計算過程中我們可以發現,這兩個分布是沒有交集的。對于特定X來說,要么分子為0,要么分母為0,最后計算都無法進行。
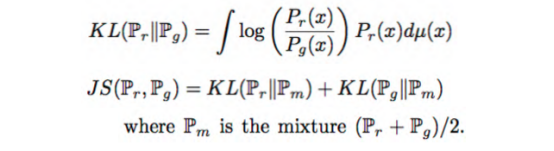
JS距離是基于KL距離的,使用的是兩個分布÷2的公式。因為兩個分布很有可能其中一個值為0,所以取平均數。計算發現,無論真實樣本還是生成樣本,兩個值一個是1,另一個就是0,結果使得JS距離為一個常數。做深度學習和神經元網絡模型訓練,我們最不希望遇到一個不變的常量,因為如果遇到,意味著它要么是一個無用的參數,要么它就是最后我們計算出來的損的值,如果這個值是一個常量保持不變,也就意味著我們的梯度沒有了。最后模型的訓練就會出問題。
【WGAN給我們帶來的啟示】
1、不要使用基于KL距離或者JS距離的梯度。
WGAN的建議是EM距離,輸入X樣本,輸出Y,Y并不是一個0~1之間的數,而是一個圖片。這是WGAN一個創新的地方。

2、讓生成樣本集合和真實樣本集合之間有可度量的重疊。
比如:給真實樣本加噪音。這個噪音可以是高斯分布,也可以是平均分布。加噪音的原因是只有這樣的樣本,才和隨機生成的樣本之間有可度量的交集,才能產生梯度,有了梯度,就可以訓練生成器和辨別器。
(二)Energy-Based GAN (EBGAN)
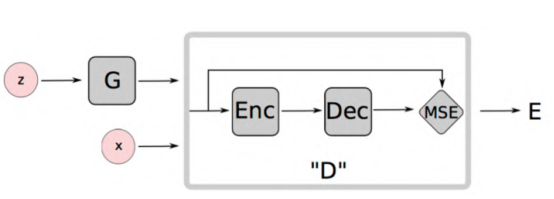
G指生成器,z代表隨機向量,x代表真實樣本。中間矩形框出的是辨別器,辨別器由Encoder和Decoder兩部分組成。
這個模型輸入的不管是真實樣本還是假樣本,都是圖片,輸出也是圖片,比較兩張圖片是否一致。大家可能覺得奇怪,這不就是復制嗎?是的,但在復制過程,先編碼生成一維向量,然后一維向量經過解碼,恢復圖片,再與原始圖片比較,如果是真實圖片,我們希望兩張圖片完全一樣;如果是生成圖片,我們希望兩張圖片的差別越大越好。這改變了在最早GAN模型中用0和1區分真實樣本與生成樣本的做法,也避免了上面WGAN中發現的梯度為0的情況發生。
Encoder-Decoder中間會生成一個語義向量,這個語義向量圖上沒有畫出來,但是非常重要。這個向量可以看成是輸入向量的一個語義,因為照片之間進行圖像操作非常困難,但是向量之間是可以加減乘除的,這樣使得我們操作一個人臉改變他的表情,甚至變成另一張人臉的過程是平滑自然的。這就是這個語義向量做的事,如果沒有Encoder-Decoder,這個事情就做不成。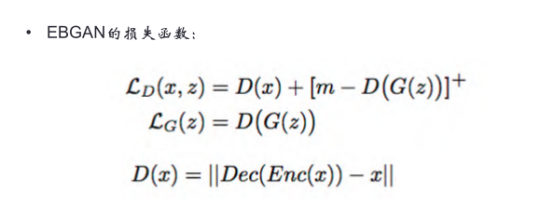
EBGAN定義了一個D(X)函數:X經過Encoder編碼,再經過Decoder解碼后,得到一個X的預測值,我們希望這個預測值跟X是無差別的。
在這個過程,我們希望真實樣本的輸入與輸出之間的誤差D(x)越小越好,生成樣本的輸入與輸出之間的誤差D(G(z))越大越好,整個公式就是判別器的損失函數Lost。m-D(G(z))指里面的數如果小于0,整個值就取0;如果大于0數,則這個數是幾就取幾。這么做的原因是,如果不加m-函數的限制,D(G(z))可以變成無窮大,前加負號就變成無窮小,Lost函數本來就希望無窮小,最后就會沒有最小值。用梯度下降法對這個Lost求梯度是沒有意義的,用這樣的所謂梯度去優化模型,肯定沒有結果。所以大家在做模型時,一定要注意:可以對函數求極值,條件是這個極值能達到,而且這個極值不是正無窮也不是負無窮。
另外,把-的誤差改成+的誤差,就是對生成器的優化。
(三)Boundary-Equilibrium GAN(BEGAN)
BEGAN模型,D函數就是之前的D函數,t指的是計算過程中第幾輪訓練,不斷進行優化。
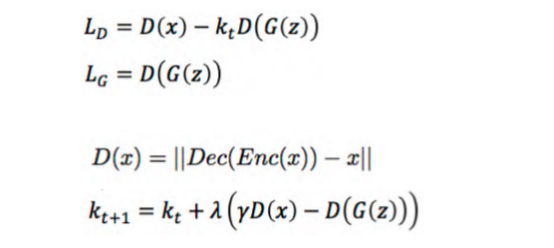
小結
對GAN的研究分為兩個方向,一個是試圖使GAN的精度提高,使生成的圖片越像照片;第二個是令它的功能更強大。上面主要講的是第一個方向,這里再強調一下,GAN在質量提高這條線上的模型,遠不止上文介紹的三個。下面我們講第二個方向,GAN的應用很強,從功能上,我們有哪些模型可以考慮。
二、功能方面—GAN的三種模型
(一)CGAN-條件生成式對抗網絡
這個模型的樣本是帶有標簽的,比如輸入一個樣本,同時需要帶上性別標簽,表示要求生成一張男人/女人的照片。這個模型是對原始GAN的一個擴展。
對判別器的訓練:真實樣本和標簽,同時輸入到判別器,輸出要么是0要么是1。
對生成器的訓練:隨機向量和標簽,同時輸入生成器,然后標簽和生成樣本同時輸入判別器。從輸入的結構角度看出,真實樣本的輸入由真實樣本和標簽組成,而假樣本的輸入也是由假樣本與標簽組成,這個訓練GAN模型的提高是一個比較大的進步。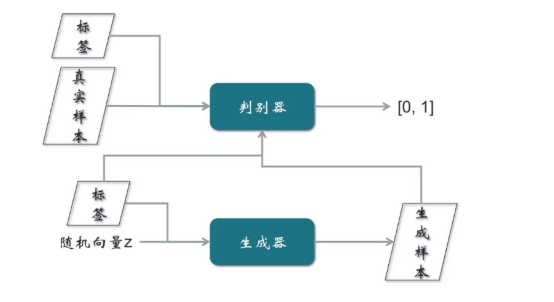
(二)Pix2Pix模型
這個模型同時也是一個應用,它的功能是手畫一個鞋子或者包的線條,可以變成一個真實的鞋或者包的圖片。這個模型的輸入過程與上文CGAN一樣,唯一區別是不需要隨機向量,只需要把簡筆畫作為生成器的輸入。
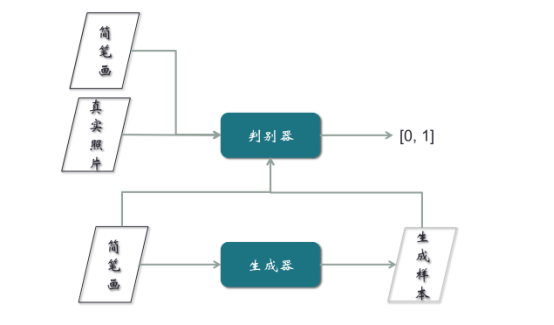
但是Pix2Pix在訓練時,需要簡筆畫與真實樣本,必須是成對的。比如簡筆畫是鞋子的線條,照片就需要是那張鞋子的照片,成對輸入。然而樣本的收集非常難,現在95%以上的時間、精力和費用都在樣本的收集上,所以要簡筆畫與真實照片配對,非常不容易。這是Pix2Pix模型的一個重大缺陷。為解決這個缺陷,提出了CycleGAN的概念。
(三)CycleGAN
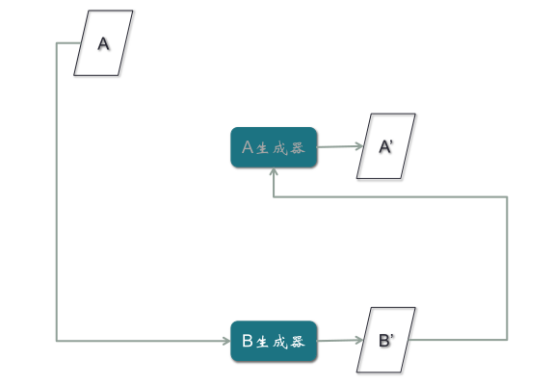
以上文簡筆畫為例,CycleGAN只需要兩類,一類是簡筆畫,一類是照片,不需要一一配對,其它功能與Pix2Pix完全一致。但是取消了配對的限制,使得對樣本收集的負擔大大減輕。CycleGAN模型的結構,它有兩個判別器,兩個生成器。其中,B判別器和B生成器是為B圖片做一個GAN模型,A判別器和A生成器是為A圖片做一個GAN模型。
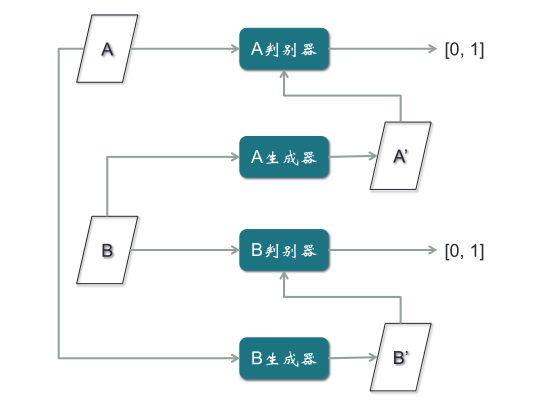
【CycleGAN的訓練步驟】
第一步,用A的真實樣本訓練A判別器,用B的真實樣本訓練B判別器,使得判別器對兩類不同真實樣本,分別都判別為1,這是從最早普通GAN模型擴展出來的。

第二步,B真實樣本輸入A生成器,輸出假的A樣本A’,然后通過A判別器,輸出為0;第二條路徑是A真實樣本輸入B生成器,輸出假的B樣本B’,再通過B判別器,輸出為0。
第三步,B真實樣本經過A生成器,生成假的A樣本A’,再經過B生成器,生成假的B樣本B’,目的是使假的B樣本與B真實樣本誤差最小。注意:B’與B之間的誤差,所產生的梯度應該去訓練A生成器,而不是B生成器,因為B生成器輸入的是A樣本,與這條路徑沒有關系,所以梯度不應該影響B生成器,而應該優化A生成器。
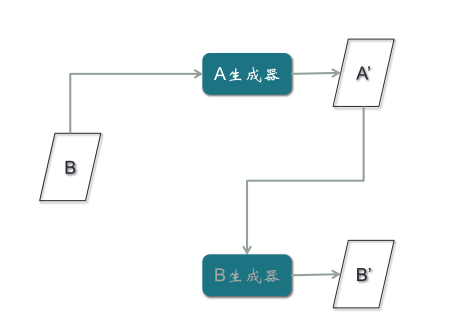
第四步,對A樣本重復第三步驟,期望A’與A一致。如果不一致,產生的梯度用來訓練B生成器,與A生成器無關。這是很巧妙的一個結構。
(本文來源于:Boolan首席AI咨詢師—方林老師)
[免責聲明]
文章標題: gan的模型
文章內容為網站編輯整理發布,僅供學習與參考,不代表本網站贊同其觀點和對其真實性負責。如涉及作品內容、版權和其它問題,請及時溝通。發送郵件至36dianping@36kr.com,我們會在3個工作日內處理。









